Churn analysis use case tutorial¶
Survival analysis is a statistical method used to analyze time-to-event data. It helps us understand the time it takes for an event to occur, such as failures, recoveries, or customer churn. This technique considers censored data, where events are not fully observed. By estimating survival probabilities and using models like Cox proportional hazards, we can uncover factors influencing the event occurrence.
This tutorial provides a foundational understanding of survival analysis, data preparation, and model building to gain valuable insights from time-to-event datasets. Let's dive in!
For the purpose of our analysis, we used a dataset representing different churn data from Telcom (a telecom company) customers.
The dataset includes information about :
-
Customers who left within the last month : the column is called Churn
-
Services that each customer has signed up for : phone, multiple lines, internet, online security, online backup, device protection, tech support, and streaming TV and movies.
-
Customer account information : how long they’ve been a customer, contract, payment method, paperless billing, monthly charges, and total charges
-
Demographic info about customers : gender, age range, and if they have partners and dependents
Note
The dataset used in this tutorial represents a group of 7043 Telcom (a telecom company) customers who churned (resigned their subscription) or not from the company and for each customer, 21 columns representing some of their characteristics such as the payment method they use for their subscription and the tenure (number of months they stayed with the company).
You can download here the dataset example used in this tutorial and to follow it step by step !
Create a project¶
As a user of papAI, you will be directed to your project homepage upon logging in. This page displays all the projects that you have either created or are collaborating on with other members.
To start a new project, simply click on the New project button, which will open a pop-up window with various settings to fill in. These settings include the name of your project, a brief description, the persistency setting, and the sampling technique you wish to apply. You can choose the number of samples to be displayed and the order selection, such as the first or last N rows or randomly.
Once you have filled in all the necessary settings, you can finalize the process by clicking on the Create button. Your new project will then be automatically added to your main page, ready for you to start working on. With papAI, starting a new project has never been easier!
Here is a video showcasing the creation of our project on papAI
Import datasets¶
Thanks to the variety of data sources available, you have the flexibility to import data from virtually anywhere into your papAI project for analysis and visualization. Whether it's from your local machine, an external database (SQL or NoSQL), cloud storage, or an API, papAI makes it easy to bring in data for analysis. Additionally, you can even create a completely new dataset using the specialized Python or SQL recipe editor.
To get started with importing your data, you can use the tools provided in the papAI interface. For our specific use case, we'll be importing our dataset from our local machine using the appropriate tool. You can access this tool by clicking the plus button located in the top right corner of the interface or by using the Import dataset button in the Flow interface.
Once you've selected the local import option, a new interface will appear that allows you to easily import any tabular file in CSV or XLSX format. You can import your desired files either by clicking the Import button or by using the drag-and-drop feature.
Once your data has been imported, you can preview a subset of the data to verify that it was imported correctly. After ensuring that everything is in order, you can simply select the Import button to start the uploading process. A progress bar will keep you informed of the status of the upload, and when it's complete, your dataset will be ready for use in your project's flow.
Here is a video showing you the process of data import of our telcom dataset
Visualizing and analyzing the dataset¶
Once you've imported your dataset into papAI, you can begin exploring its content and obtaining an initial analysis to determine the cleaning steps necessary to extract the most valuable insights from your data. However, before diving into preprocessing, it's essential to explore the structure of the data through data visualization.
If you want to take your data analysis to the next level, you can also use descriptive statistics to uncover trends and better understand how your data is distributed. In papAI, you can easily access these statistics by selecting the Statistics tab from the table interface.
This interface allows you to quickly view the key statistics for each column in your dataset, including the median, mean, and standard deviation. Additionally, you can view graphs that illustrate the distribution of your data, such as box plots and histograms, to get a more comprehensive understanding of its characteristics.
By analyzing these descriptive statistics, you can gain a deeper understanding of your data and identify any potential outliers or trends that may require further investigation. This information can then be used to inform your preprocessing and modeling decisions to create more accurate and reliable results.
In our case for example , we can see how many observed people churned from Telcom , and the different payment methods used by Telcom customers.
Here is a video showing you some customers statistics
Clean your data¶
After running your different data exploration steps, you are ready to configure your cleaning steps in order to obtain a ready-to-use dataset and develop the most robust model.
In order to access the cleaning module on papAI, you just need to select the desired dataset from the flow and select from the green operations of preprocessing on the left sidebar the cleaning icon. When selecting it, a new interface will be displayed with a preview of the dataset and a right bar where all your cleaning steps will be stored.
Starting your cleaning process comes through the plus button on the top right. The different cleaning steps are classified by categories such as Cast, Format, Filter, Extract…. In the case of the selected dataset for Telcom customers churn, we only have one special operation to apply which is anonymization of customerID, or in other terms, encode/hide the customer IDs for security purposes.
All you need for this operation is selecting the Anonymization category in the list of steps and choose the Anonymize column step. Afterwards, you just need to select the column CustomerID. When you are done, press the Save and Run button to launch the process.
Here is a video showcasing the cleaning steps applied on the dataset
Note
You can apply more complex operations through Python or SQL scripts if you are more familiar with these programming languages.
Train and test the model¶
At this stage, your dataset is set be used for training and testing some models and choose the right one in the end to be deployed in production.
Prior to accessing the Machine Learning module, we split the dataset into two separate datasets : one for training and the other for testing. The splitting can be triggered by selecting the dataset and then the split rows operation from the green icons in the left sidebar. Clicking on the icon will display a pop-up to tune up some settings related to the split such as the name of the two newly created datasets, the splitting order (for our case it will be 85 and 15%) and the splitting method. When all set up, we click on the Save and Run button to apply the split.
Here is a video showcasing the split operation applied to our dataset
Churn analysis with survival models¶
We can launch the ML process by pressing the training dataset and then the ML Lab icon. It will give you access to the ML Lab where you will be testing different models. But first you will need to define the use case you want to tackle.
Creating a ML use case is very simple since you need to click on the New use case button. Through a pop-up, you can choose the type of the use case required to answer it, for our case, we will try survival models.
For a survival model, you will also need to fill up some fields such as the survival duration (tenure here), the event status :
churn here, and a survival class, 0 here. Finally, you just name your use case and click on Create to access to the ML Lab and save your runs.
Here is a video showing the ML pipeline creating process for survival analysis
Interpret features impact on churn with Cox model¶
With its powerful Survival Analysis functionality, papAI make users gain invaluable insights into their datasets by employing the Cox Proportional Hazard (CoxPH) model to measure the impact of various features on survival, particularly in the context of churn analysis. The CoxPH model enables us to assess how specific factors influence the likelihood of churn, shedding light on crucial patterns and drivers that can significantly impact business decisions and customer retention strategies.
Here is a video showing papAI feature coefficient and partial effect features
Predict future churns¶
We add a prediction model to the ML process by pressing the training dataset and then the ML Lab icon. It will give you access to the ML Lab where you will be testing different models.
But first you will need to define the use case you want to tackle. The same way for the previous model, we create a new use case but this time using binary classification and for this type of model, you will also need to fill up some fields such as the target, churn here, and a positive class, Yes here.
Finally, you just name your use case and click on Create to access to the ML Lab and choose your the models you want to run for your experiment and save them.
Here is a video showing papAI binary classification run using 5 different models
Evaluate and Interpret the model¶
The evaluation of each model is crucial since one of them will be used for our prediction of customers potentially quitting the company and our prediction needs to be accurate and avoid potential errors that could lead into serious issues for the company.
Thanks to the ML explainability module, we can display a number of tools and plots that explains in detail the model decisions for the prediction and understand the underlying mechanism that the algorithm went through. In order to access to that module, you only need to select a run from the list of runs in your use case.
Warning
The run needs to be successful in order to access to the module. If it's not the case, either rerun your pipeline or check any parameters that could affect the process.
You will have access to the XAI module related to that trained model you chose. The first part of this module being the evaluation where you can monitor the performances of your model through metrics such as accuracy, precision, recall, ROC AUC score... but also plots such as confusion matrix, ROC curve... All of these tools are essential for the user to judge the model's robustness and decision making.
Here is a video showing papAI's interpretation and evaluation for binary classification models
Test the prediction made by the model¶
Coming to the final step of this tutorial, you chose the right model to deploy it for your case but you still need to test it on the testing sample to get accurate predictions. To resolve this issue, you need to add the newly trained model into a model registry by identifying the model run, ticking the box next to it and selecting the Add to flow action from the Actions list on the top of the ML Runs list.
This will trigger a small pop-up to set up the model registry and fill up some fields such as the registry name, the recipe name and the activation method. When done, you just hit the Create button and the model registry will be created and displayed on your Flow.
Here is a video showing the model registry creation process deploying the random forest model
Here is a video showing the prediction run with the model registry we just created
Creating a model registry will allow you to calculate any prediction on a chosen dataset. To trigger the prediction process, you will need to click on the dataset and choose the Prediction icon on the left sidebar and choose the registry you want to use and click Continue.
A small popup will appear with some optional settings to tune up if necessary. When finished, you click on Save & Run button to activate the prediction process and created a new dataset included a column with the predictions of the target class.
Here is a video showcasing the prediction step triggered
Counterfactuals¶
Introducing the remarkable Counterfactual Explanations, a cutting-edge papAI module designed to empower users with a profound understanding of diverse hypothetical scenarios. Unveil a spectrum of strategic choices for engaging with customers, ensuring their retention, or orchestrating intricate maneuvers to safeguard machines from the brink of shutdown.
At its core, this innovation thrives upon the principle of tailored outcomes, allowing users to navigate the intricate pathways of customer interactions or machine operations. The module serves as a virtual compass, aligning with the user's project ambitions and aspirations. It deftly adapts, offering insights that transcend the ordinary, providing guidance that resonates with the specific objectives set forth by the user.
In our case, the Counterfactuals enables us to detect potential changes we can apply to each customer to guarantee non churn.
In technical terms, we choose the features which we can intervene by interacting with the customer (Contact, Internet service, OnlineSecurity, TechSupport, PaymentMethod), in order to set up an action plan for each customer.
Here is a demo of setting up the features on the Counterfactuals module
In the case of the prediction n°4, we go to the Counterfactuals tab, we choose the variables on which we can interact with the customer, and we get a list that shows all the scenarios that can help us avoid churn.
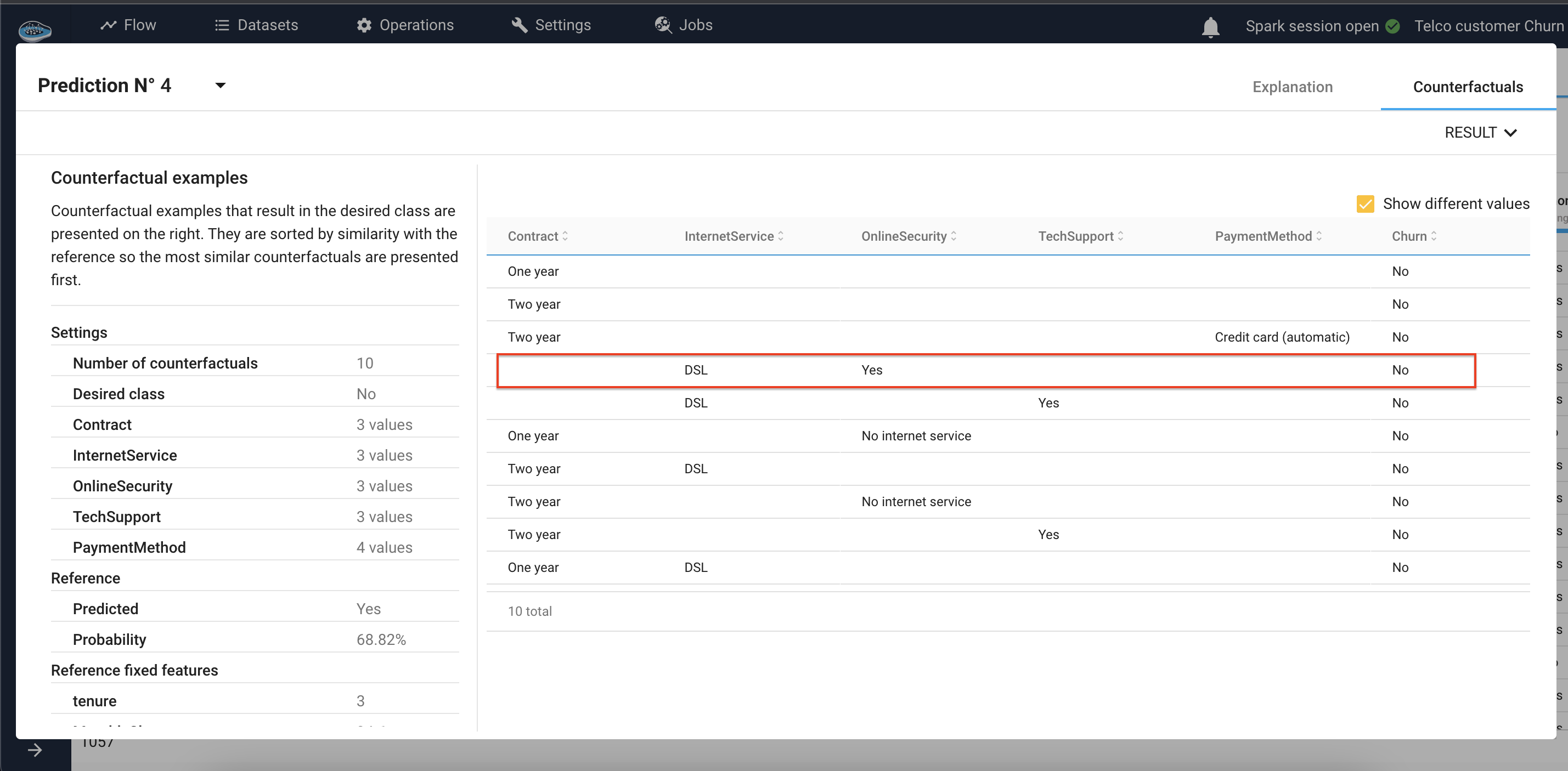
We can take an example of a scenario proposed by papAI, such as changing the customer’s internet service to DSL, and offering him online security.
Here is a demo of applying the example and applying it
In the Explanation module, we can see that for this customer, we had an 68.82% chance that he would churn, and after intervening with the Internet service and offering him Online Security, we turned the odds in our favor, so that we had a 52.83% chance that this person would not unsubscribe.
Conclusion¶
In conclusion, by adhering to these straightforward steps, you can effortlessly accomplish your own Data Science project from inception to completion, without requiring any coding expertise. Despite the absence of code, you will obtain remarkably robust and precise results promptly, fully prepared to cater to your personal or business requirements!
We sincerely hope that this tutorial has proven beneficial to you. If you desire to dive deeper into the subject, we encourage you to explore the vast array of tutorials offered in the papAI catalogue, which elucidate additional features and functionalities.