Concat¶
In some cases, the join operation is not enough and you need to apply a union operation on two datasets to create a new one containing both of them. Therefore, we include the Concat operation that will merge two datasets into one output dataset by stacking them on top of each other (vertically). This operation is equivalent to a "union" operation mainly used in SQL.
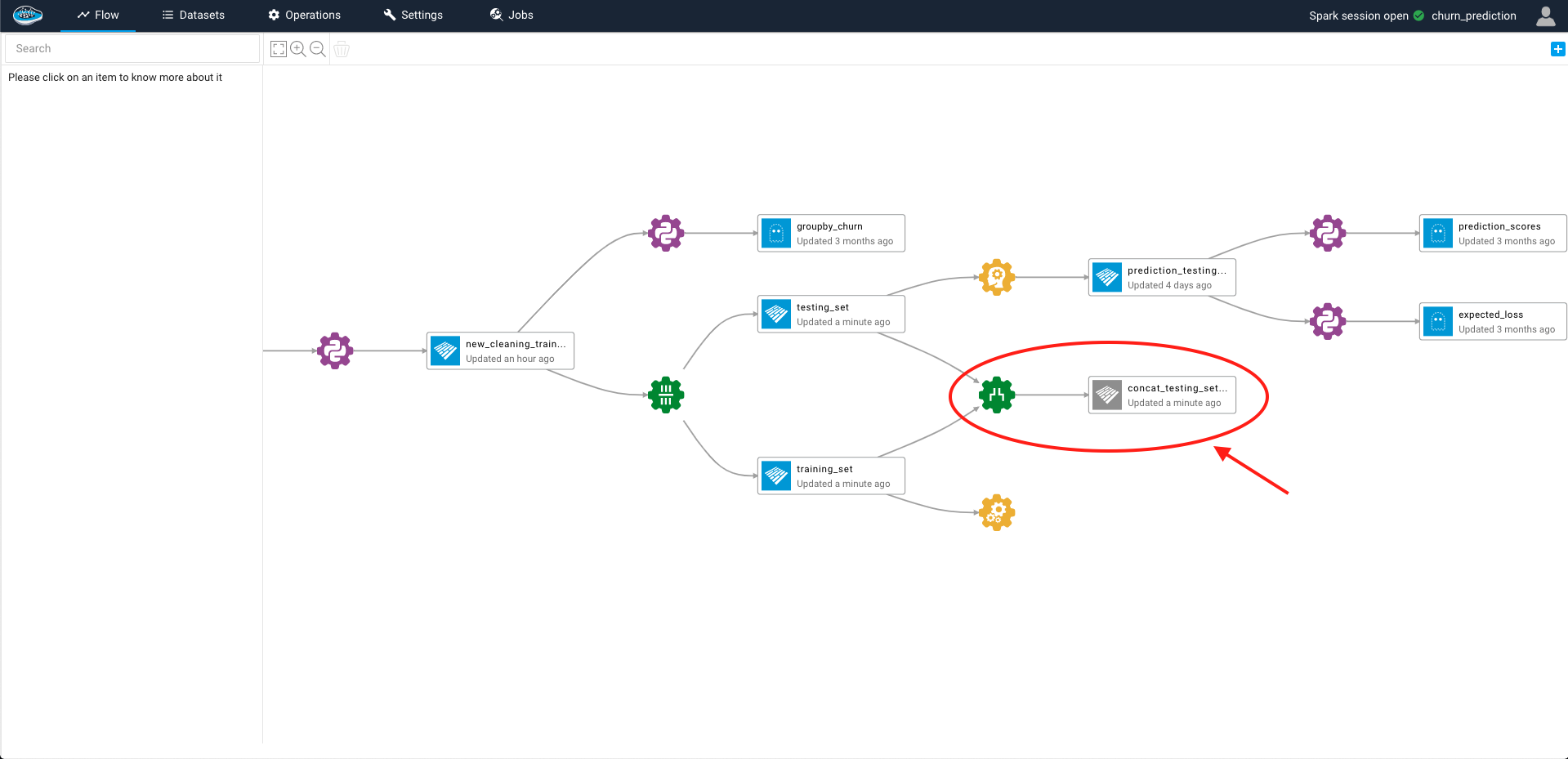
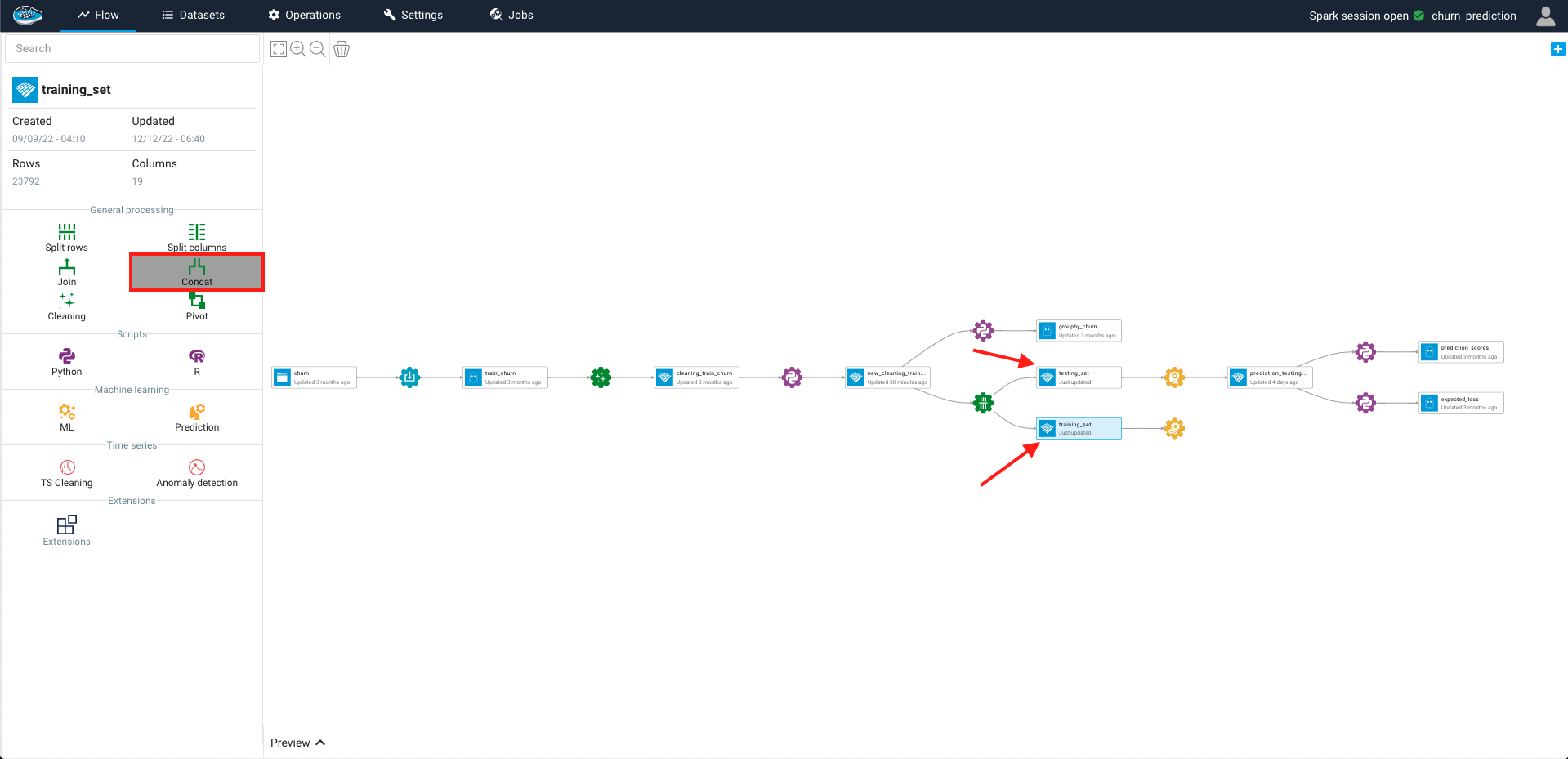
To access to this option, you need to select the first dataset and on the left sidebar, select the Concat operation and afterwards the second dataset that you want to concat with.
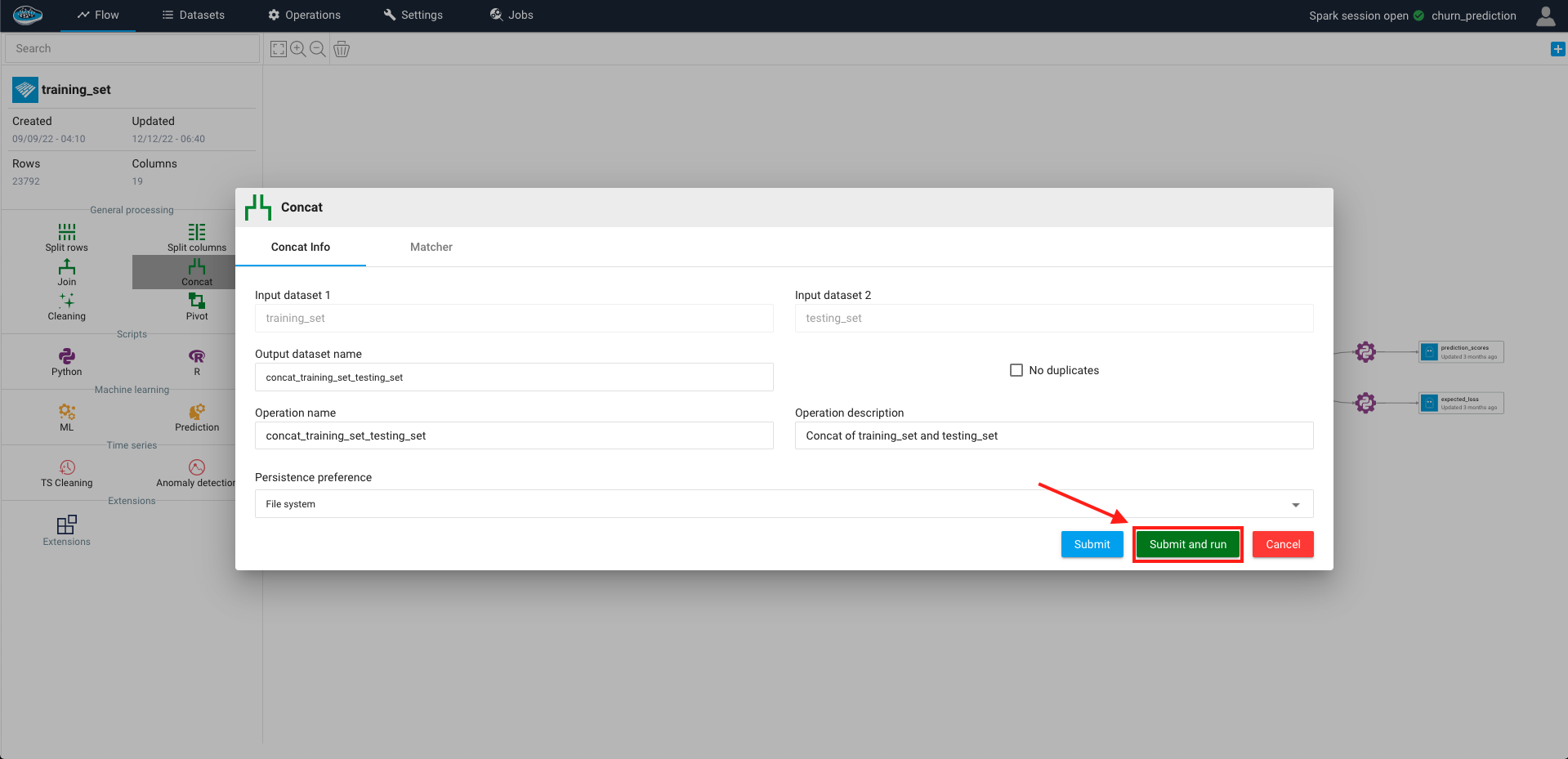
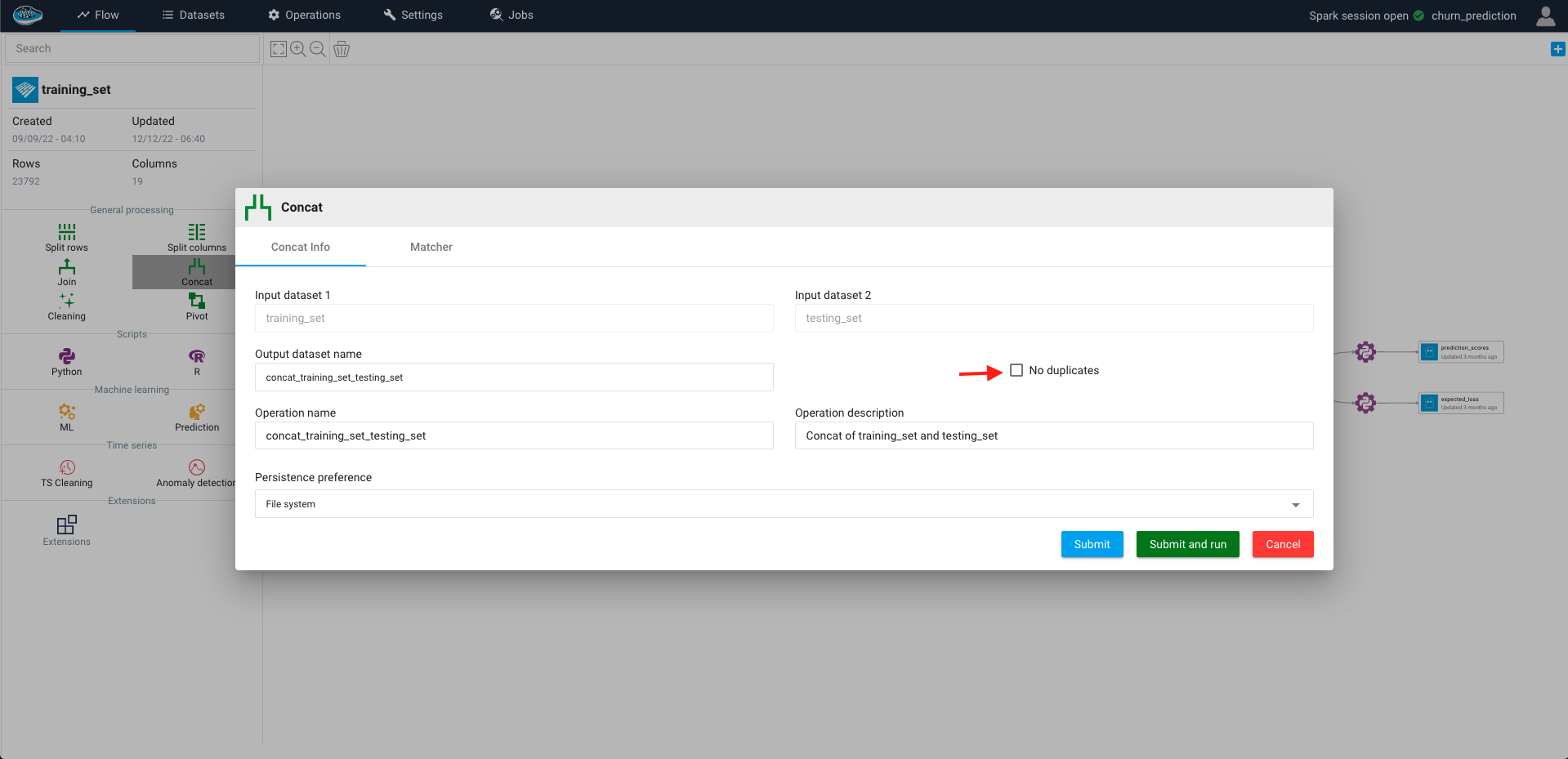
A pop-up will appear with different settings to choose from :
- Defining the output name, the operation name and description
- Define the persistence setting
- Delete the duplicated lines
Warning
In order for the operation to succeed, you need to have both datasets with the exact same number of columns with identical column names.
Tip
If you want to keep the duplicates in the output dataset, you can de-toggle the No duplicates box
Note
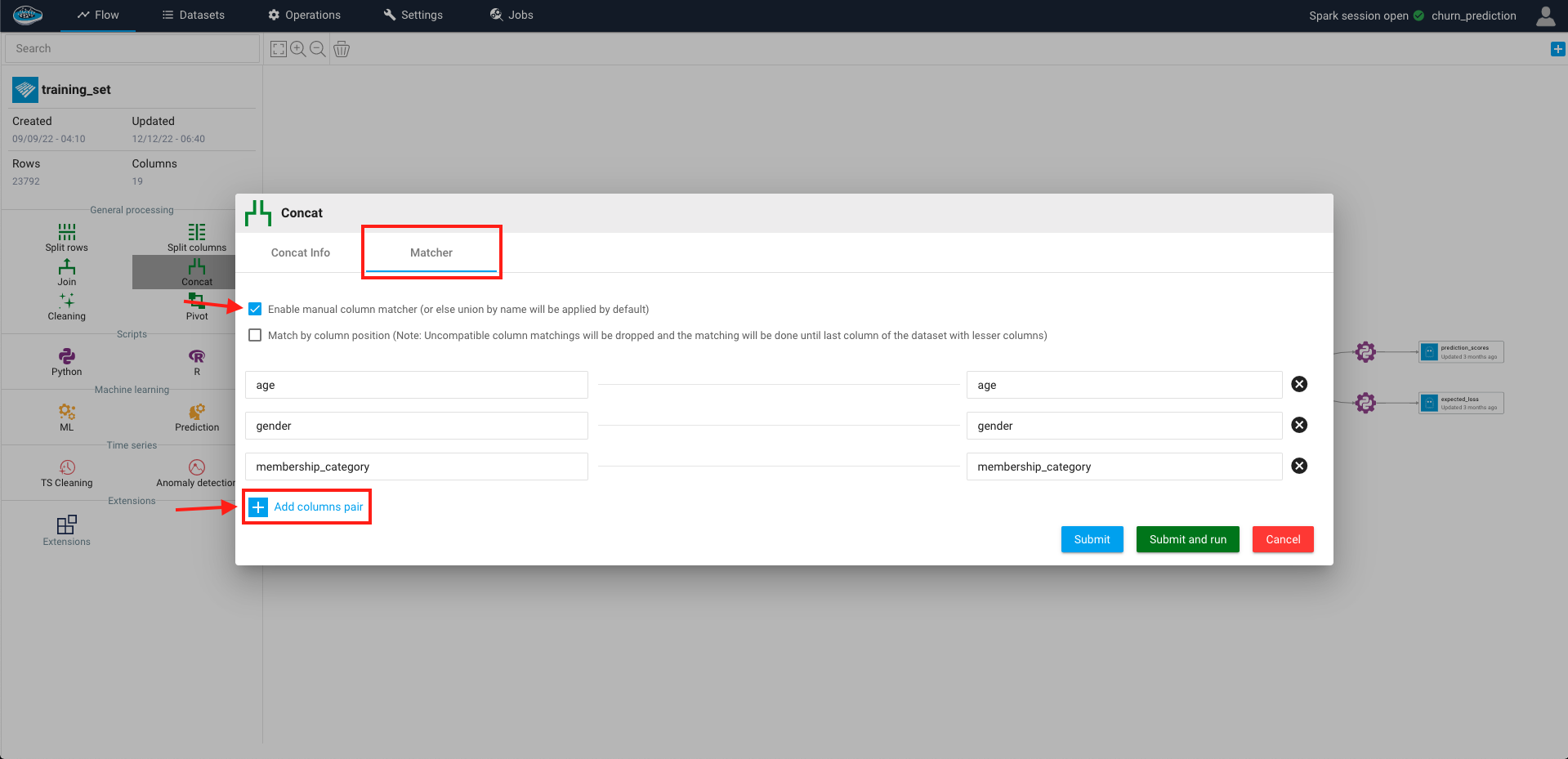
The operation will automatically detect and match the columns together to execute the operation but you can toggle the Matcher option to manually apply it according to your needs.
After selecting the right settings for you, you just click on the green Submit and Run button and a green gear representing the operation will appear linked to both input datasets and the resulting output dataset on your project's flow.