Complex operations through Python and Spark SQL recipes¶
papAI offers a huge range of possibilities and methods to preprocess your datasets from split or group by to cleaning but in case of wanting to assess your own data process rather than using the regular transformation steps, you can use the dedicated Python or Spark SQL editors to type in scripts and apply them on any dataset of your project's flow.
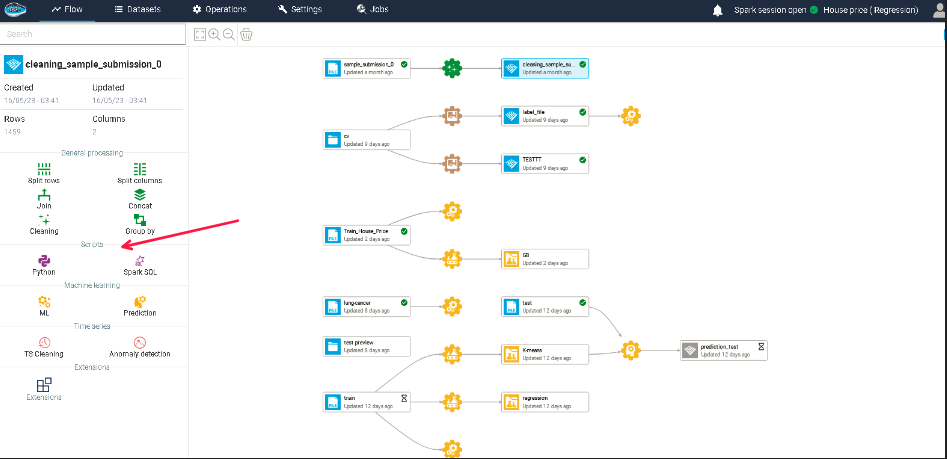
To access to these editors, you just select the dataset you want to apply your script on and on the left sidebar, select either Python or Spark SQL recipe icon, depending on your preferences.
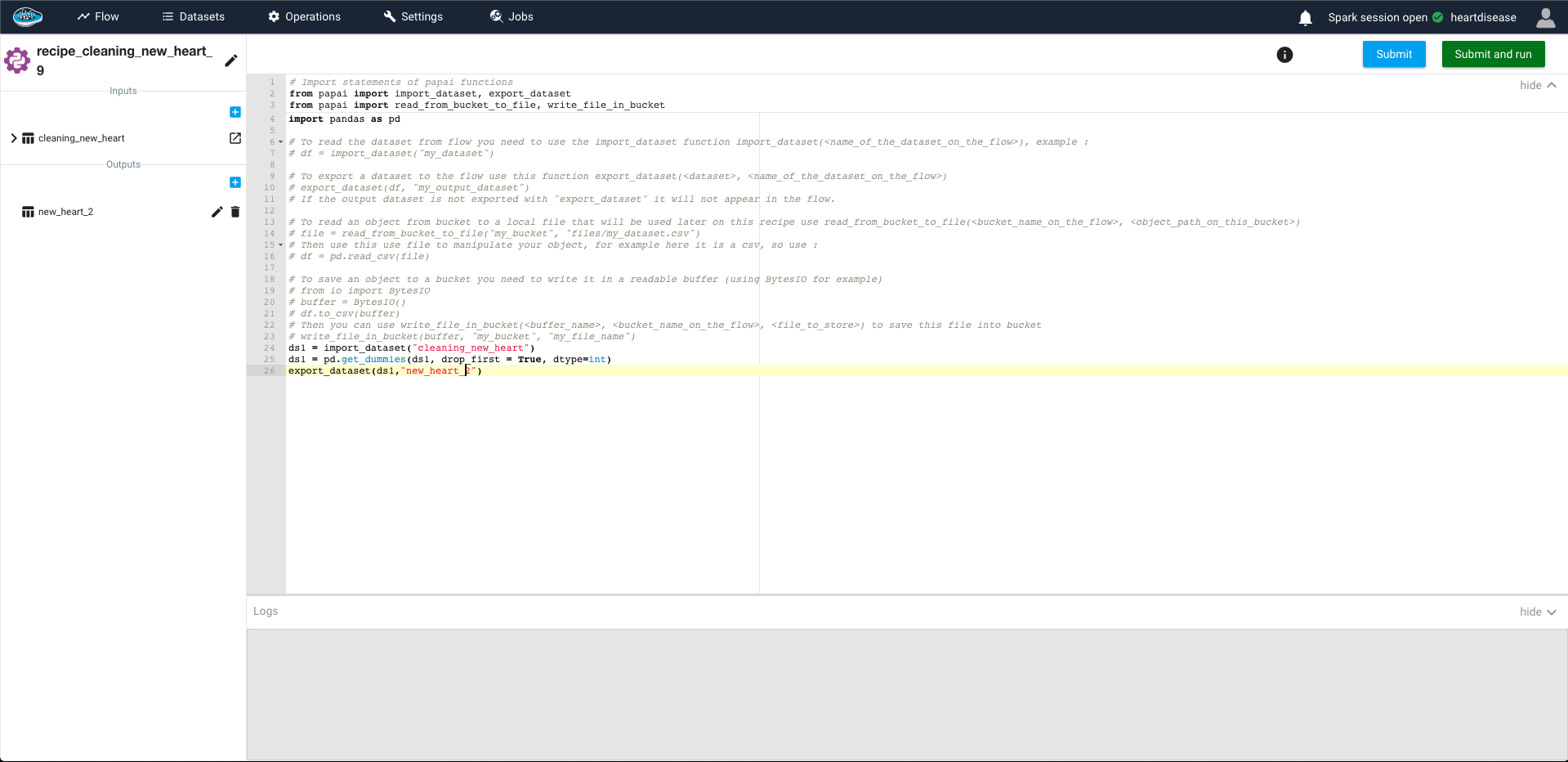
You access to the same interface as when importing a dataset through Python or SQL recipe with the same features : on the left sidebar, you have the input dataset and the output dataset where you can define the desired number datasets and their names and on the right panel, the editor with some comments to help guide you writing your own script.
Warning
The operation can't be submitted in case of not defining at least one output dataset.
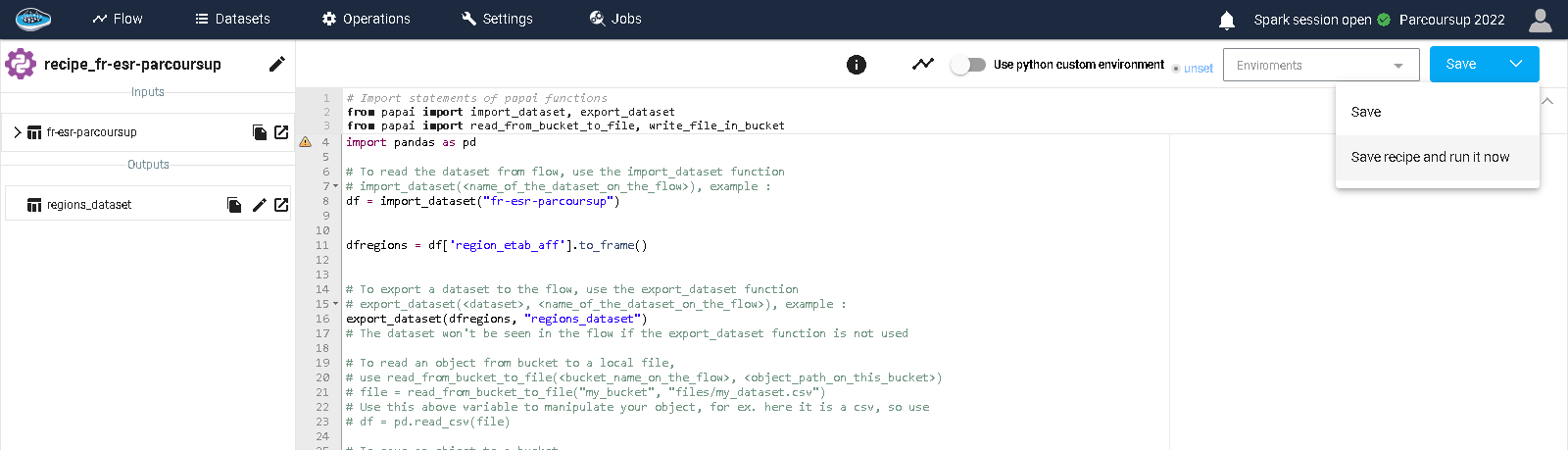
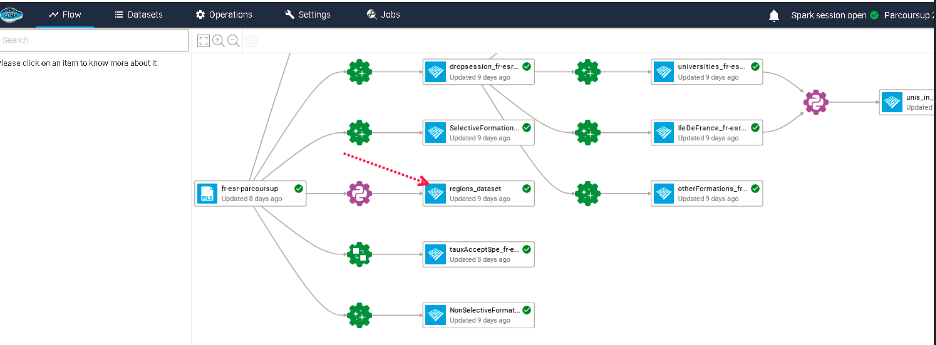
When your script is ready, you simply click on the Save recipe and run it now button on the top right corner and a violet Python or Spark SQL gear icon linked with the output dataset is displayed in your flow.
Note
When executing your recipe, a terminal displays in the bottom panel the logs of your execution. If your code contains any error, the logs will appear in the console or else it will just inform the good execution of the script.
Info
If you have no inputs, you can create your own dataset within the Python or Spark SQL recipe editor. For more info on this topic, you can click here.
Here is a demo showing the Python script editor