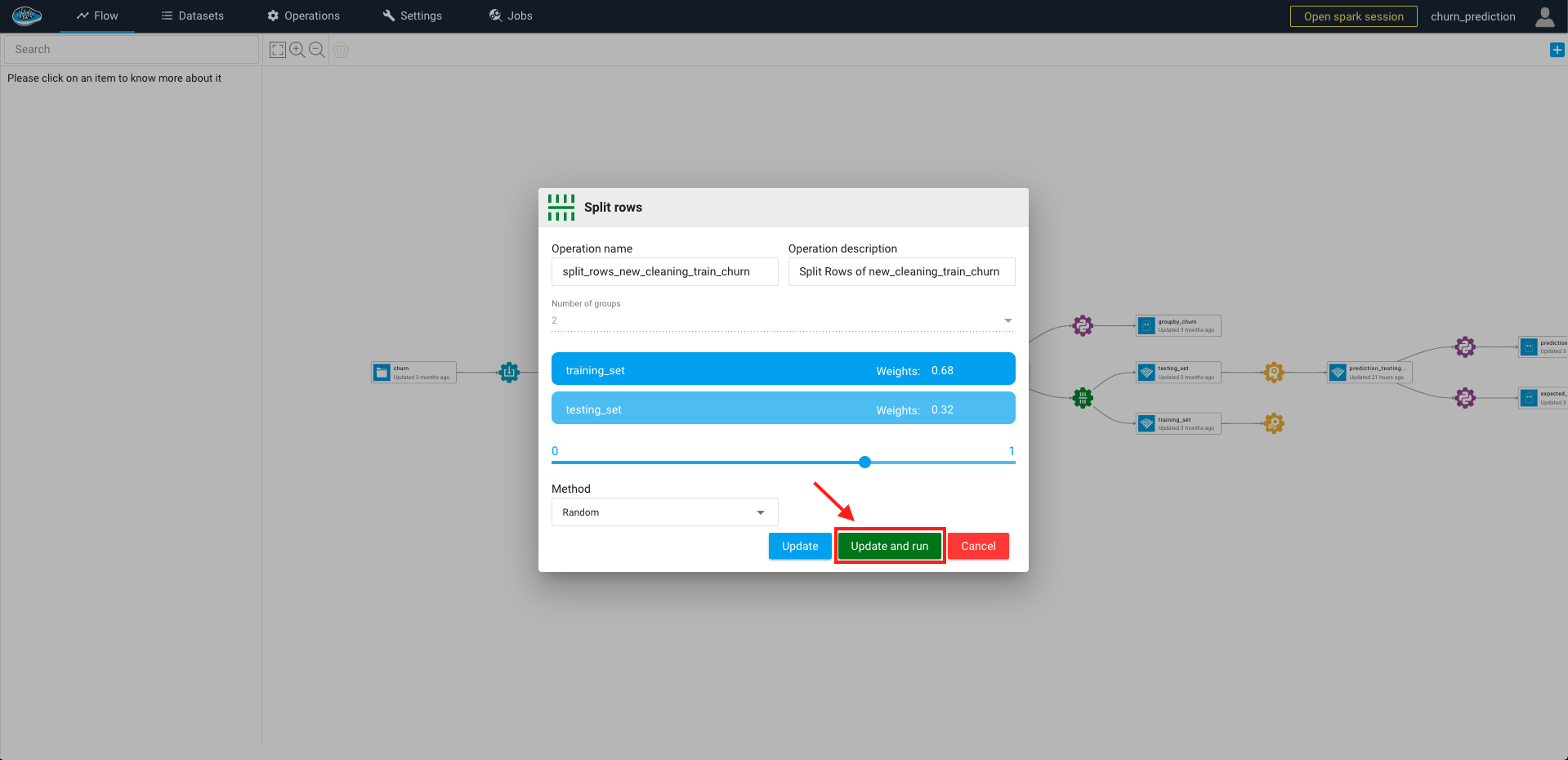
Split Rows¶
After transforming your dataset to the desired schema, the main step into building a model is the train test split to check if the model's predictive ability is correct or is mainly overfitting. This split is essential because even with a validation process, you always need a raw dataset to test out your newly built model and assess its robustness on any dataset with a similar schema. Thus this feature dispatches rows of one dataset into multiple output datasets based on user defined rules.
To access to this feature, click on the desired dataset and on the left sidebar, you select the Split Rows green icon and a pop-up will automatically appear on your screen.
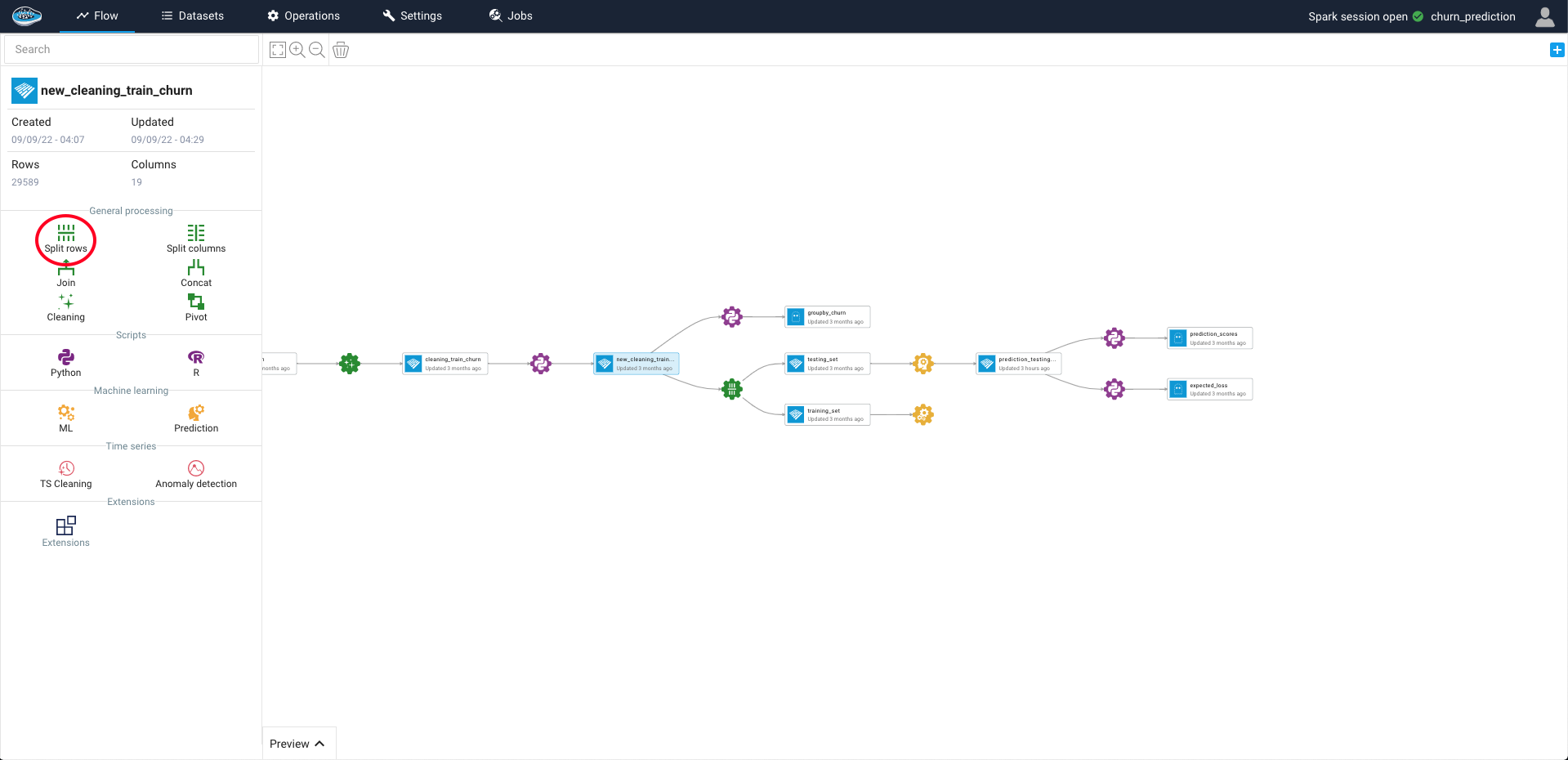
On this pop-up, you can define some rules as to the splitting method. The rules are the following :
- The operation name and description
- The number of expected output datasets : by default is 2 but limited to 4 max
- The ratio of rows given to each output dataset between 0 and 1 : by default the ratio is calculated by
1/<number of outputs>and the sum of ratios is equal to 1 - The persistence setting
- The splitting method
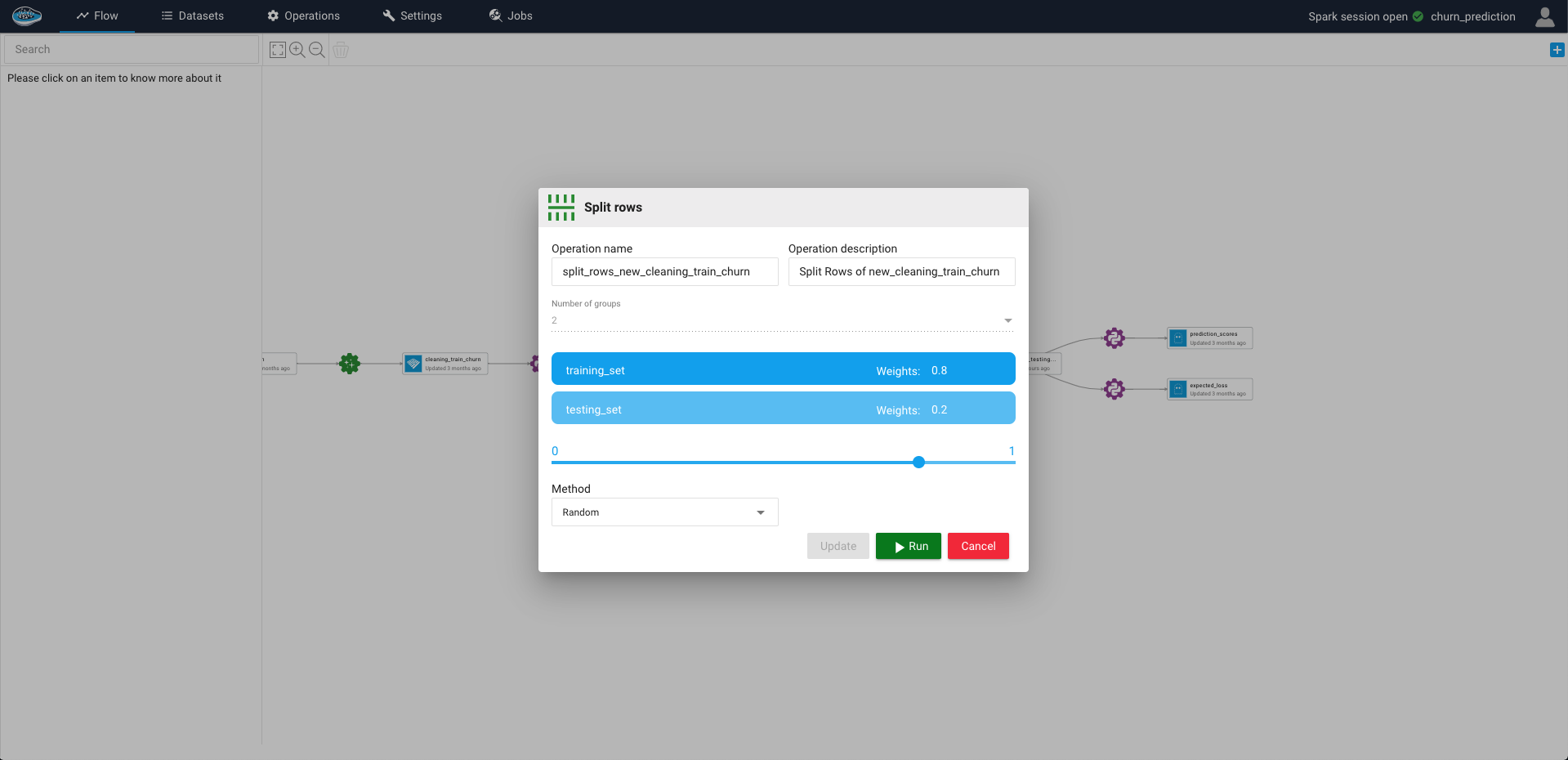
Tip
You can choose different splitting methods by selecting the Method box:
- Random: the split is applied randomly throughout the dataset
- Order By: the split is applied following the order settled in each sorted column (0-9 to A-Z)
- Stratified: the split is applied while having the same proportion of classes or values of each column
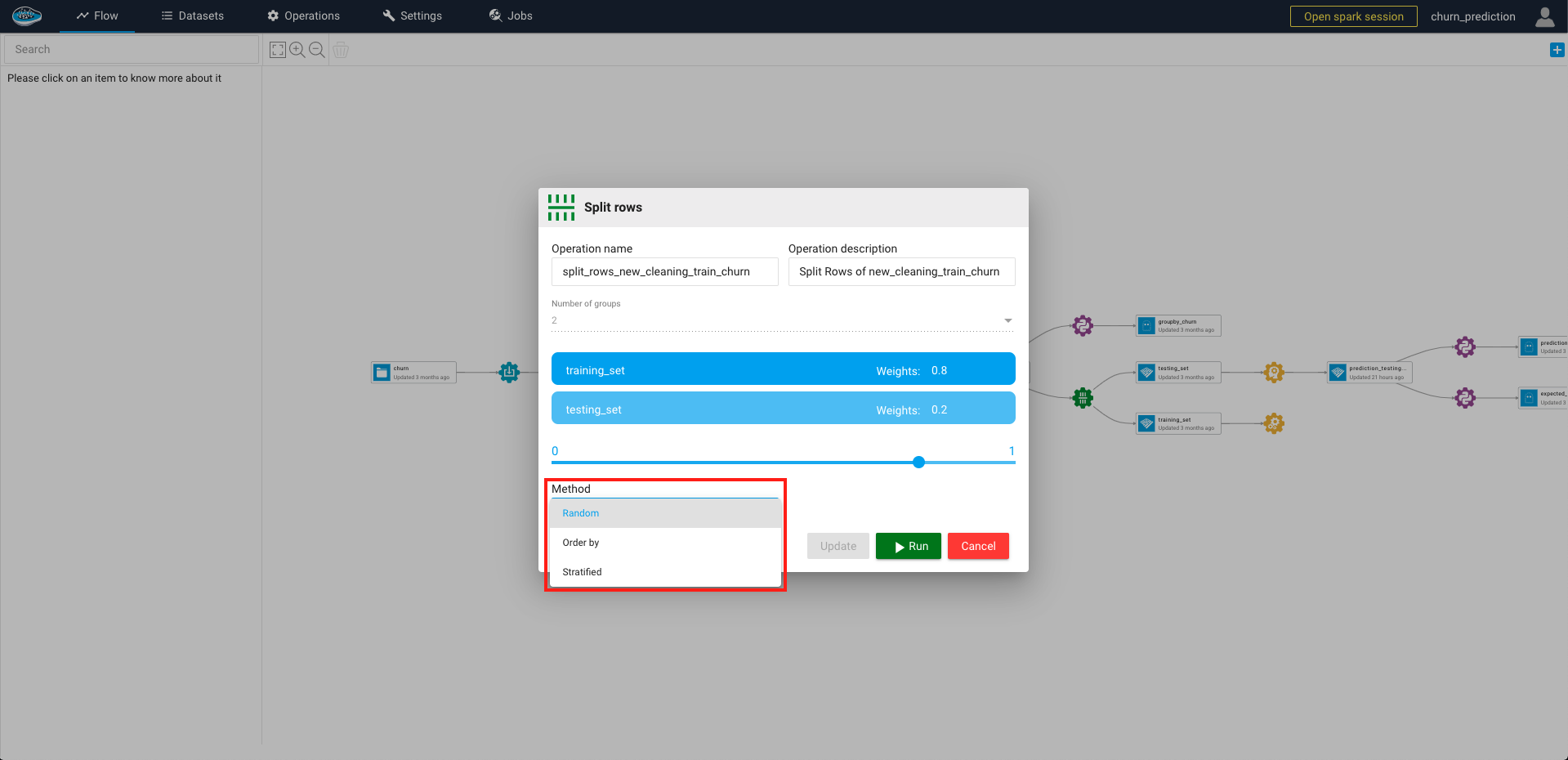
When all of the settings are selected according to your likings, you just select the green Run button and a green gear logo linked to the input dataset and newly created outputs will appear in your flow.
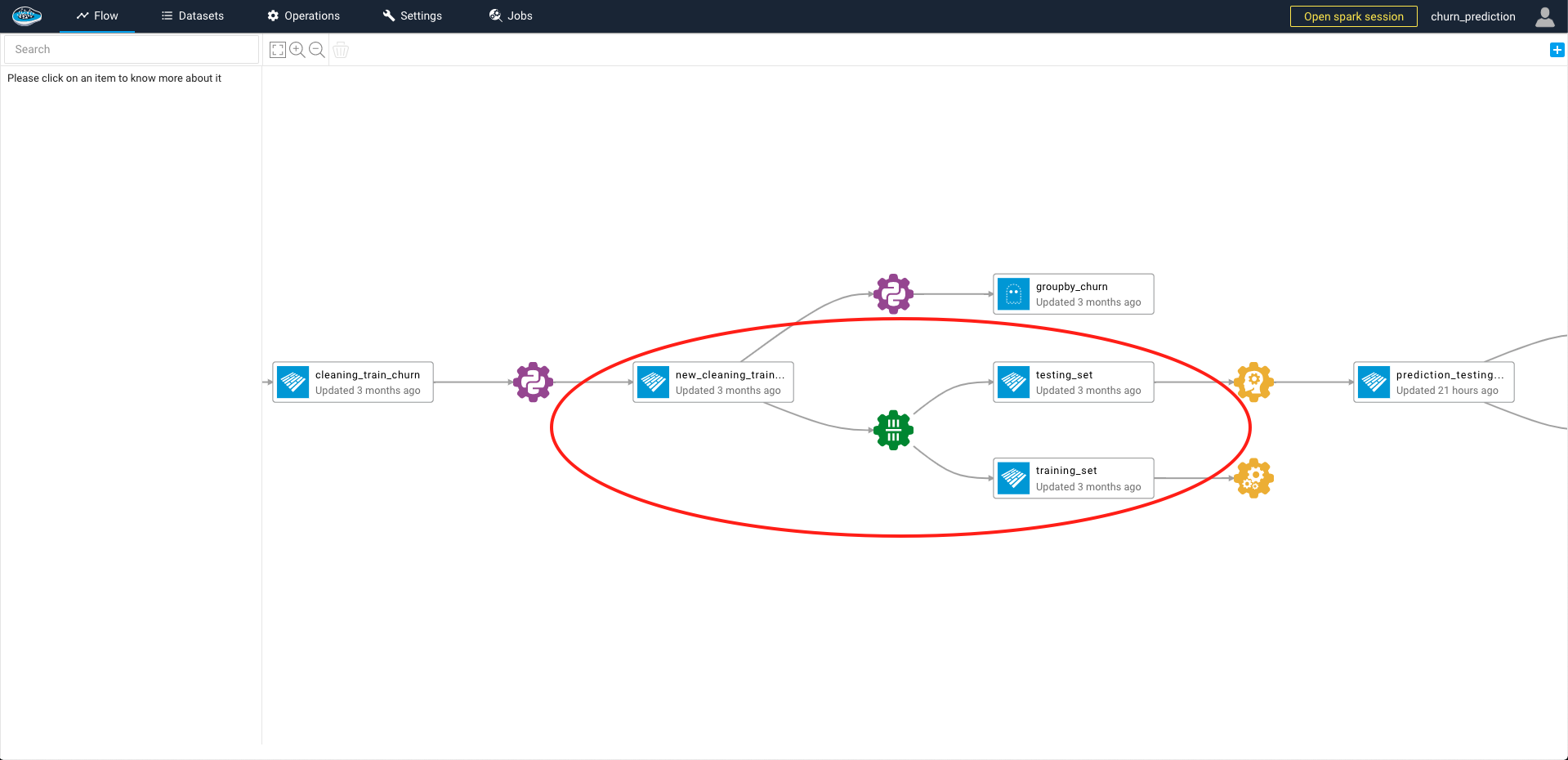
Tip
If you need to change some settings to fit your needs, you can simply click the green gear icon and change the settings and when finished simply click the Update and Run button to apply the changes onto your outputs.