Bucket type object storage¶
Sometimes in your projects, you need to use a large amount of data that can be unstructured and you can be limited with the space allowed. Hence, introducing a new type of storage in papAI : Object storage.
This type of storage is used to tackle this type of issue with storing files as objects into scalable buckets without any size restriction and easily retrieved with a unique id to each object.
In order to use this system, you need to create your own bucket through the project's homepage by clicking the same Import a new dataset button or the little icon on the top right corner and access to the pop-up listing all the data sources and select the bucket icon
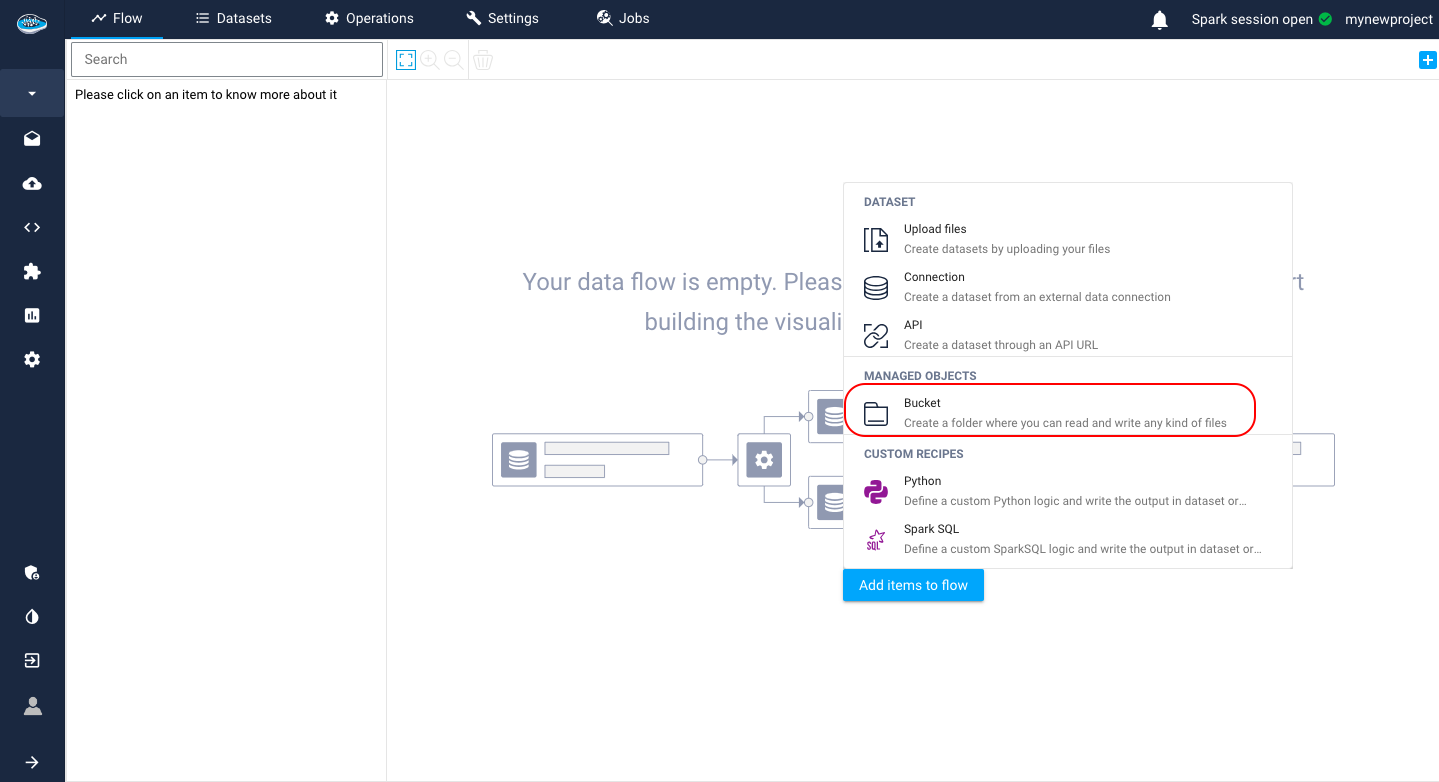
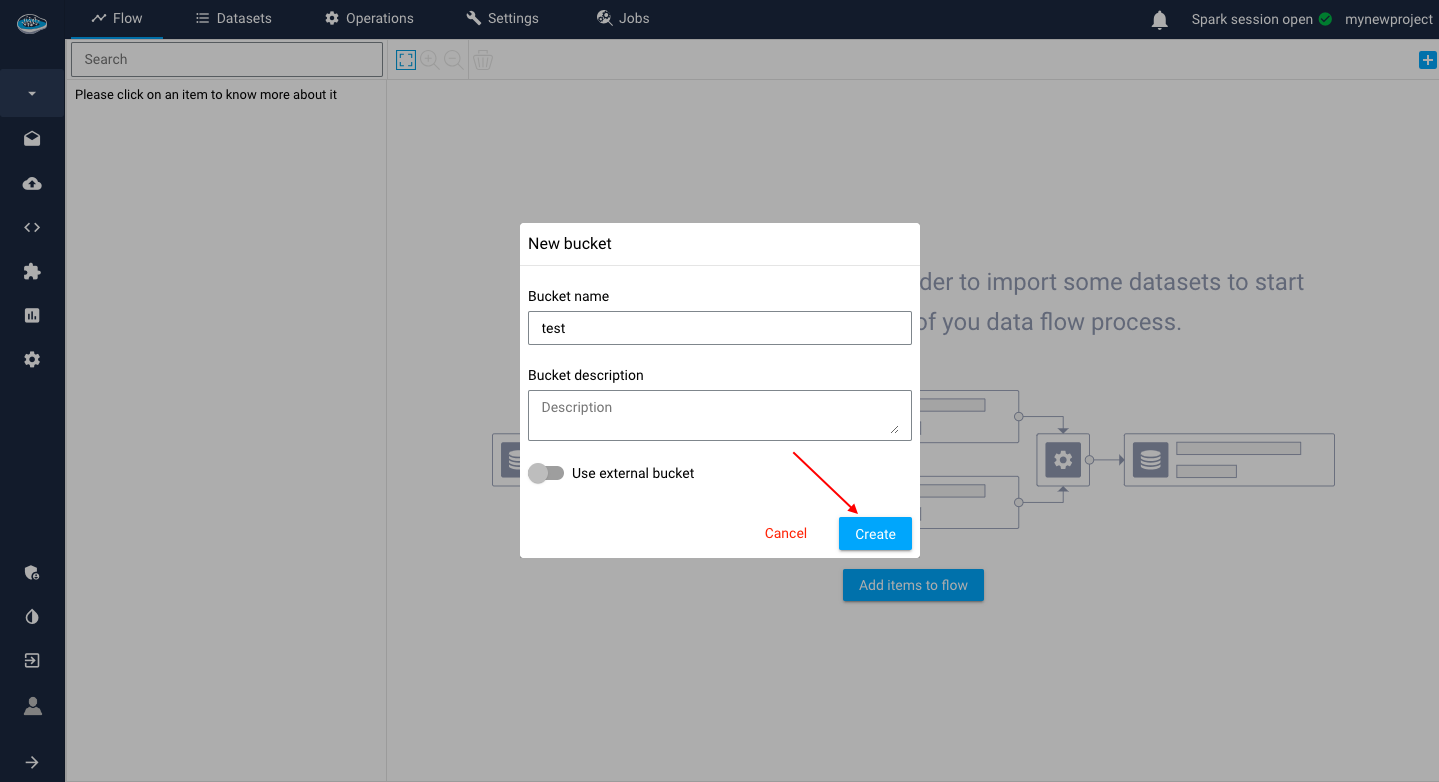
A new window will appear to create your own bucket with it's name and a description and click on the Create button.
Tip
You can import a already existing bucket stored in a Cloud storage such as Amazon S3, Microsoft Azure Blob or Google Cloud Service.
Since these connectors are already included in the plateform, you just need to create a new connection to one of these sources or use an existing one and select the desired bucket to be imported onto papAI and simply click the Create button.
The bucket will be created and appear on the project's flow. To access into its contents, you need to click on it and a new window will be shown with the objects stored in the bucket. In our case, since it's just has been created, the bucket is empty and need to be filled by your own datasets or other type of files.
All you need is to go on the icon located on the top right of the window to start uploading files through a similar interface than importing from Local Storage. You follow the same steps and confirm through the Upload button.
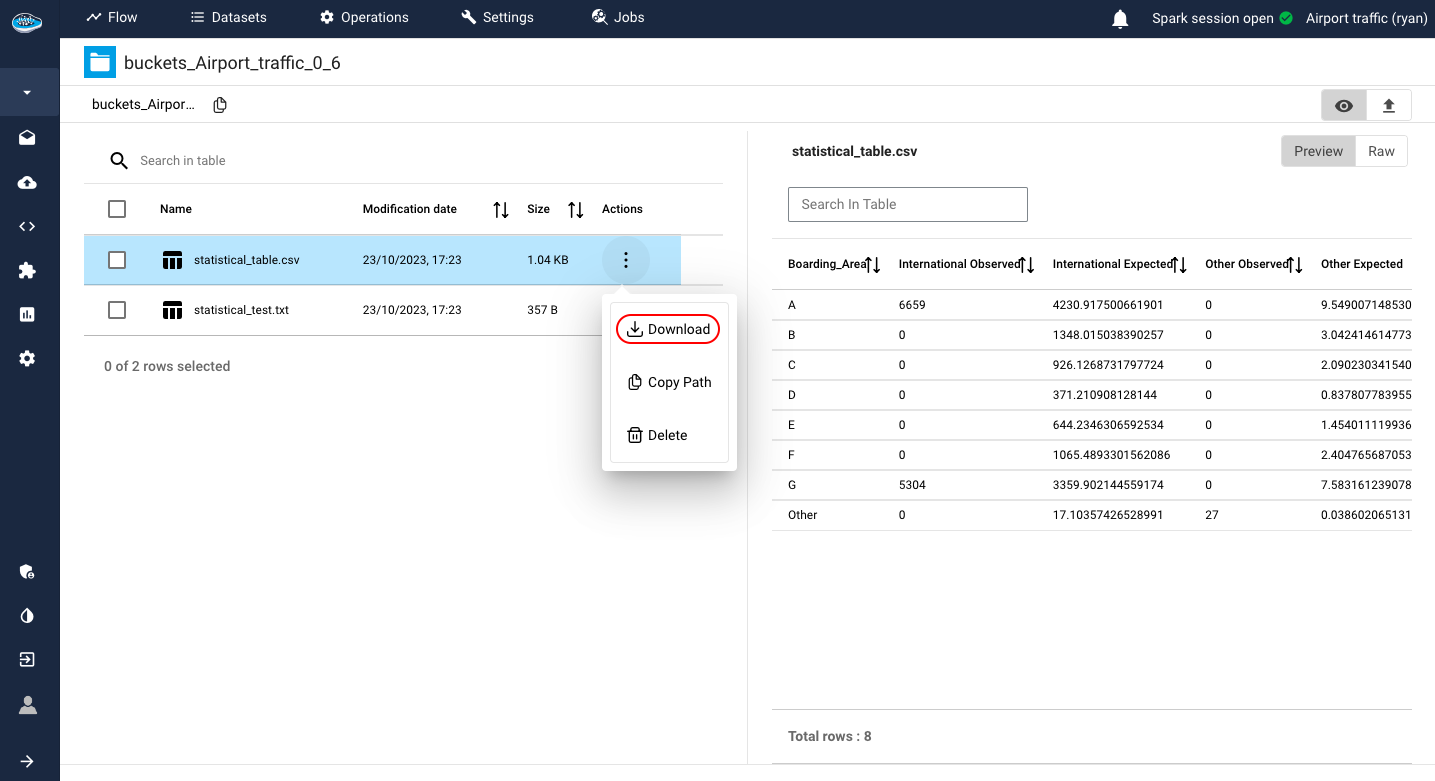
After uploading the desired files, you can take a look on its content through the Preview mode by clicking the icon. This mode can be used for any type of files such as CSV, XLSX, JPEG, PNG but also PDF or JSON files and other types of files...
Finally, you can also look at it through the file explorer tab your files and the hierarchy they follow even some metadata of each file.
After uploading your files, you can import from your bucket into your project flow and that process is pretty easy and intuitive. All you need to do is to click on the bucket that you created located in your flow and on the left section of the interface, you select the Import from bucket icon that will trigger a pop-up window. This window give you the choice to select which files stored in your bucket to introduce it into your project's flow. You select your files by clicking them and when you finish the selection, you just click the Import button on the bottom right corner of the window and all the selected files will appear on the flow ready-to-use for your different operations and create your complete ML flow.
Warning
Only tabular files (CSV or XLSX formats) are accepted by papAI to be imported into a project and transformed into datasets.
Here is a demo using bucket data source