Group By¶
The Group By operation is essential to extract useful information from raw data and summarize the contents of a dataset efficiently thus including it onto papAI. Indeed, this operation allows you to aggregate the input dataset through some columns and apply an aggregation function to it. In other words, you select the column by which the dataset will be grouped and you specify a list of aggregation to perform for each column. This list of aggregation includes :
Min, max, mean, sum, std (for numerical columns)Count, first, last (for numeric and categorical columns)
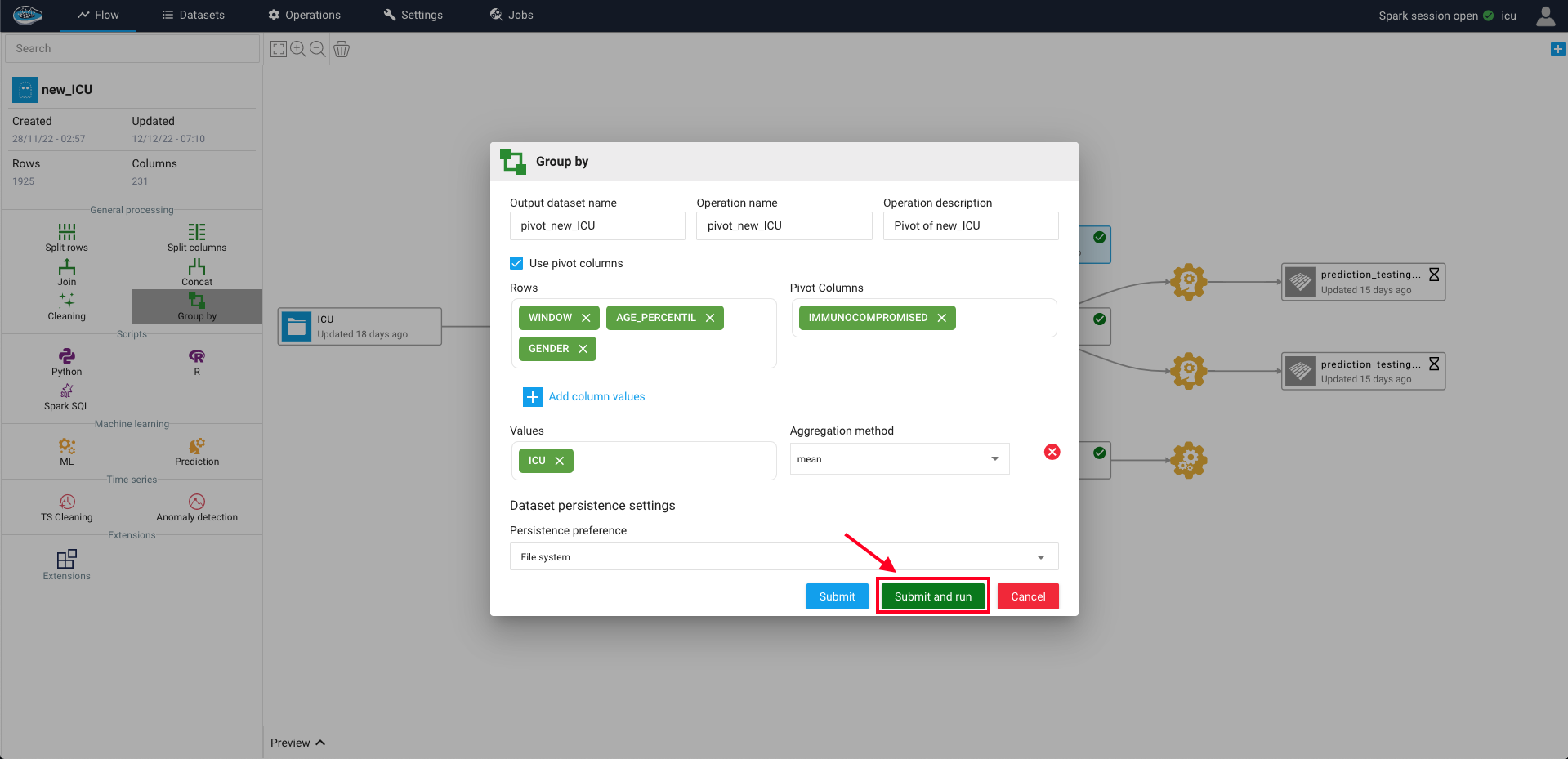
To access this feature, all you need is to select the desired dataset on the flow and on the left sidebar, select the Group By feature where a pop-up window will appear with different settings to choose from such as :
- The operation name, the output dataset name and description
- The input columns that should be as output columns with at least one input column selected
- The input columns that should be as input cell values along with the aggregation method to apply on these columns. (one input column should be selected)
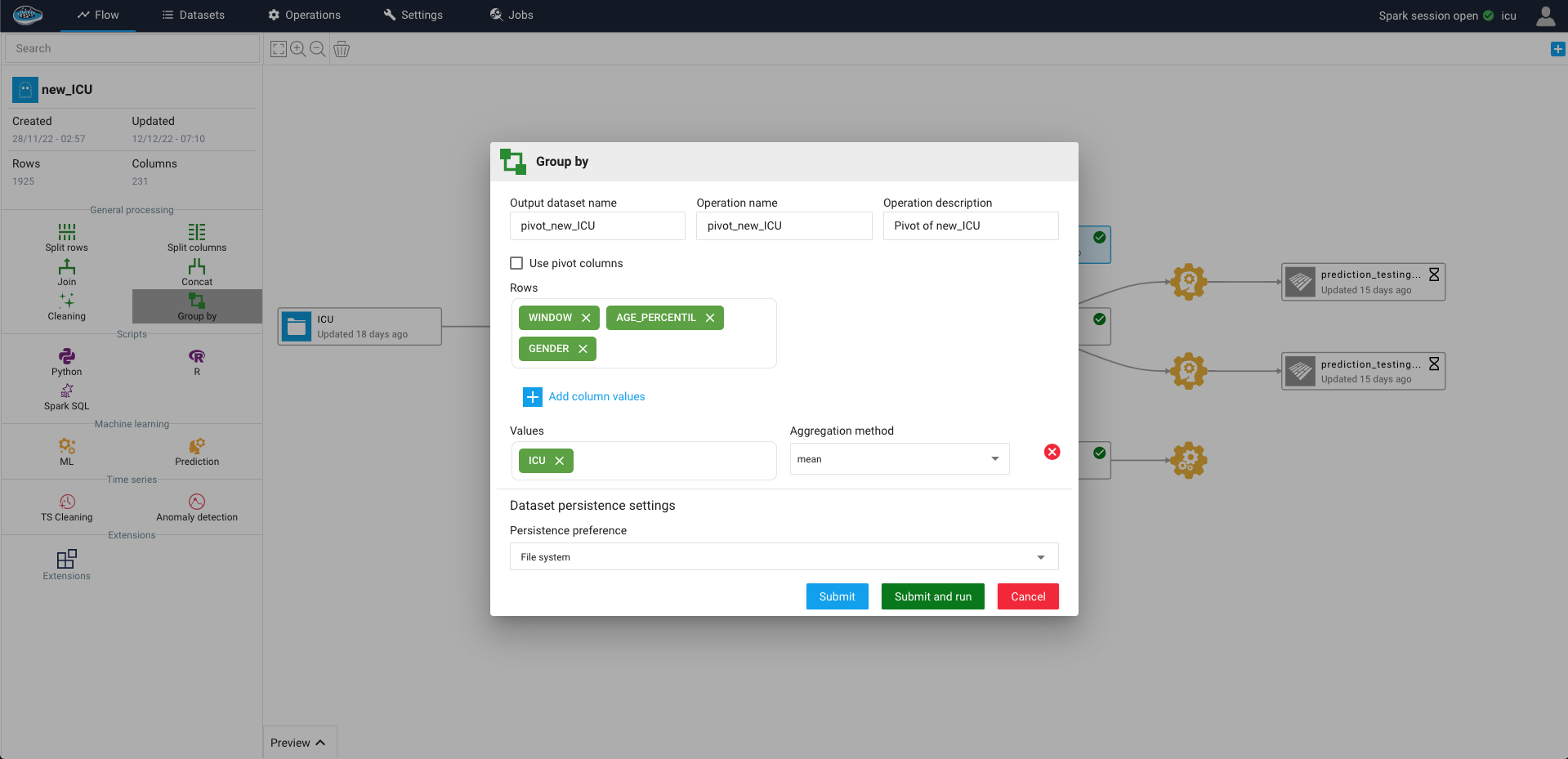
Tip
If you want to include other columns to increase the level of granularity into your output dataset, you can select them through the Select pivot columns toggle button to include them as rows in your dataset.
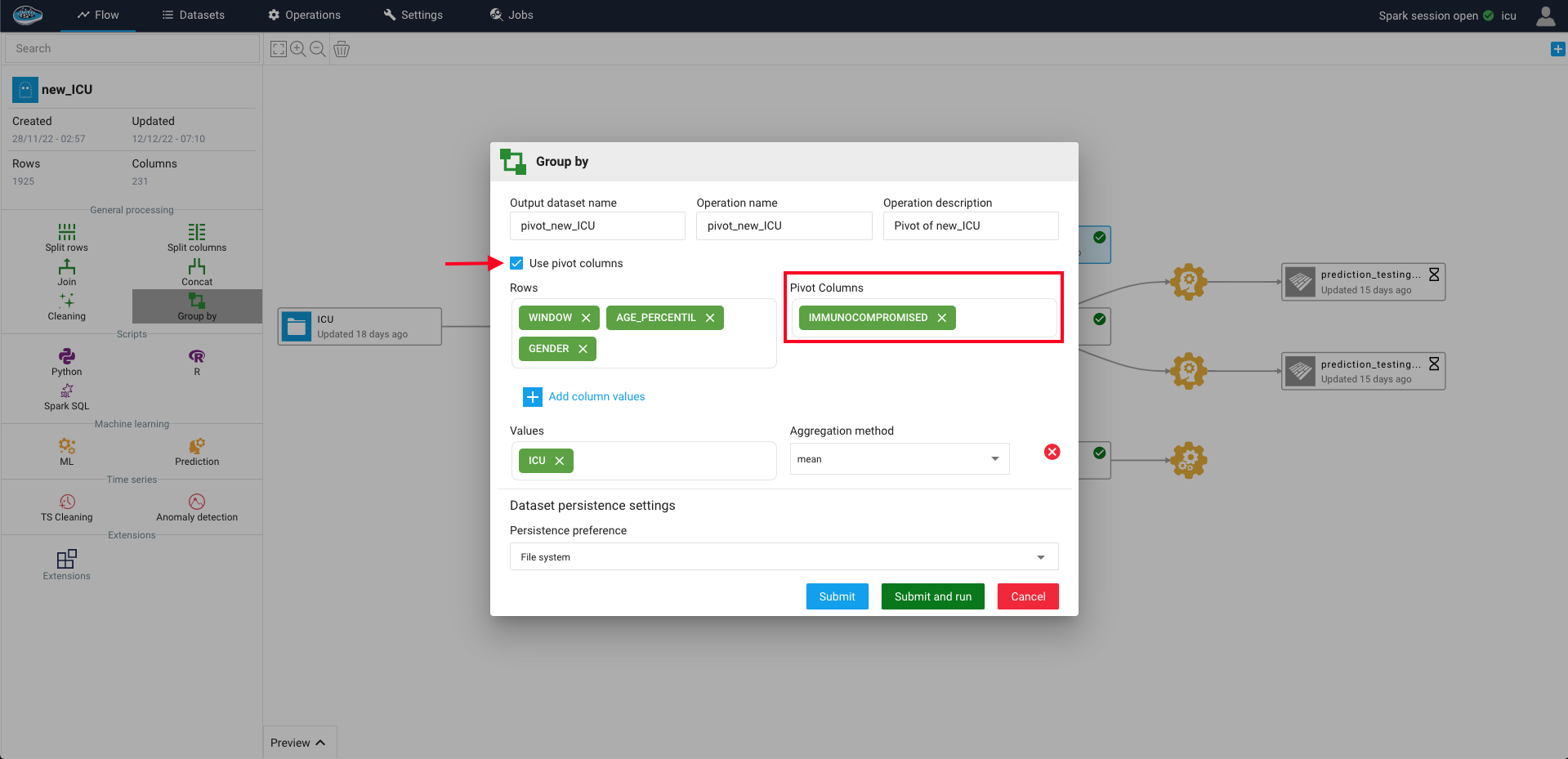
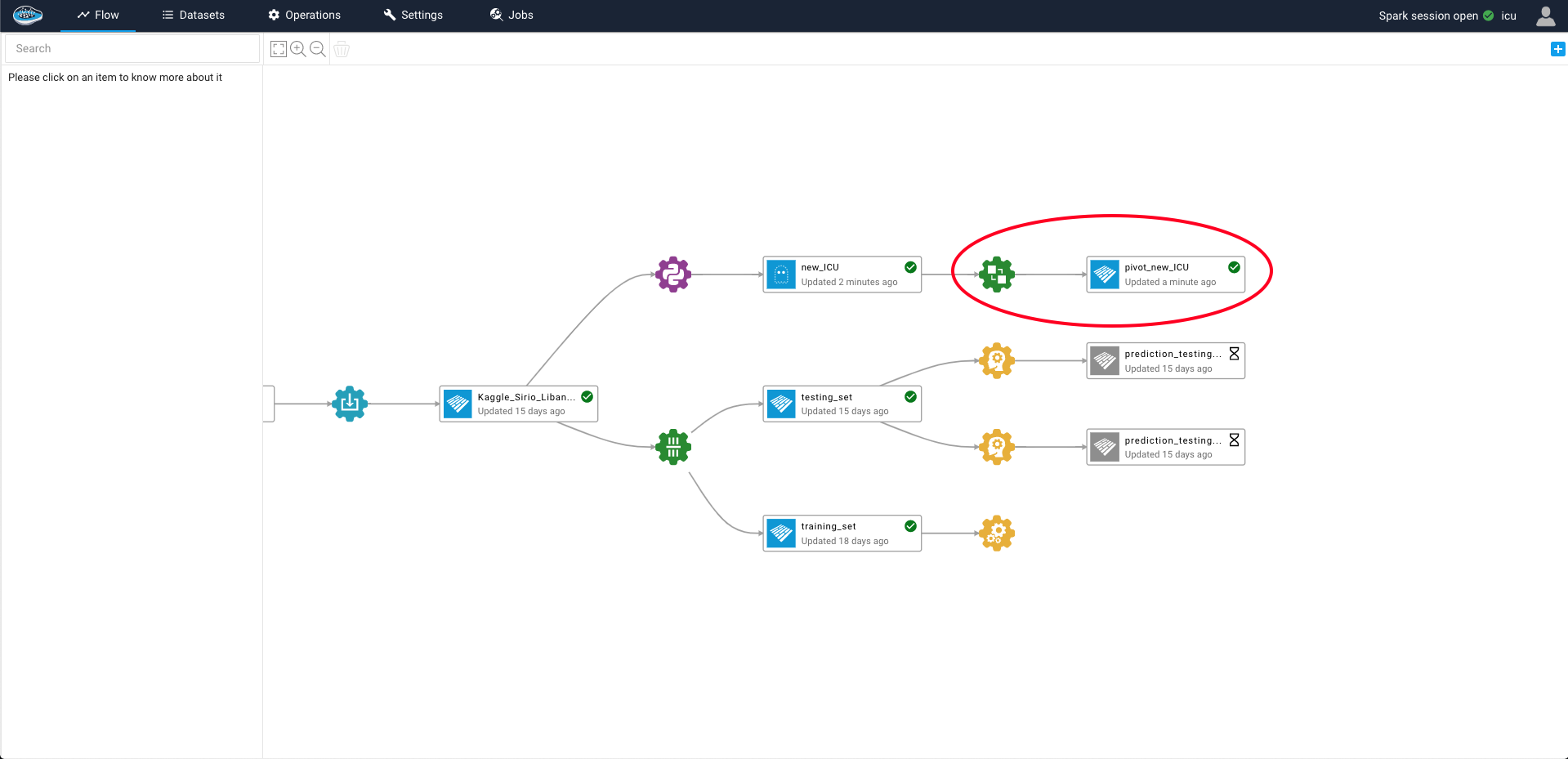
When the right settings are selected, you can run this operation by selecting the green Submit and Run button and a green gear icon linked to the input dataset and the newly created output dataset will appear on your project's flow.