Create a new ML use case¶
When done with the cleaning process and having a well structured dataset, the logical next step is to apply a Machine Learning operation to it. This AutoML module is a collection of one or multiple ML use cases including multiple experiments. Each experiment represent not only an ML model but also some data processing operations, necessary for the model training. Through the AutoML module, you can compare the performance of each experiment and pick out what corresponds best to your needs.
However, before going into the model training, creating a new AutoML use case is a must. To create an AutoML operation, you need to click on your prepared dataset and select the yellow ML gear icon on the left sidebar on your project's Flow.
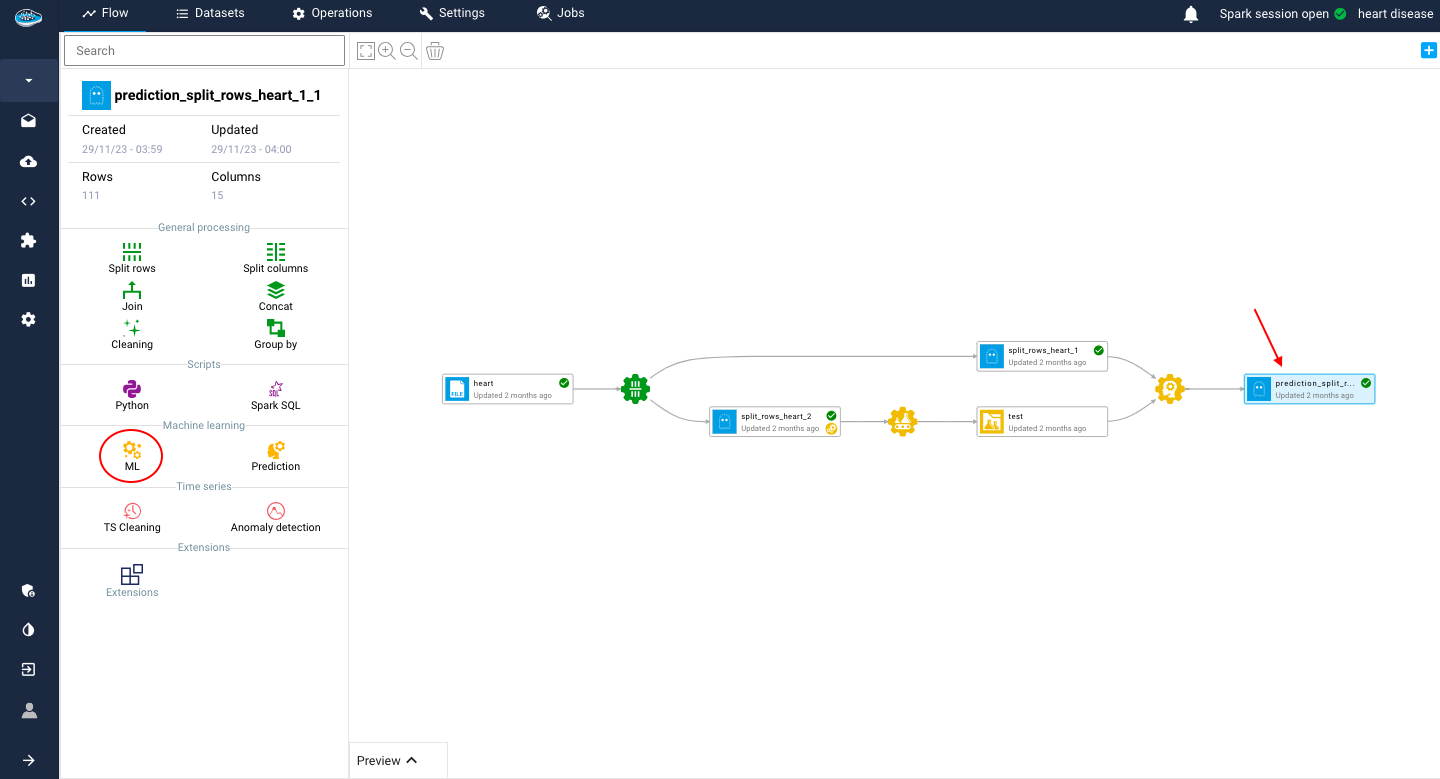
It will get you the access to the AutoML interface and specifically the use case list where you create your own use case that you need.
To create your own use case, just select the Create a new use case, either on the top right corner or in the middle of the screen (in case that is your first use case).
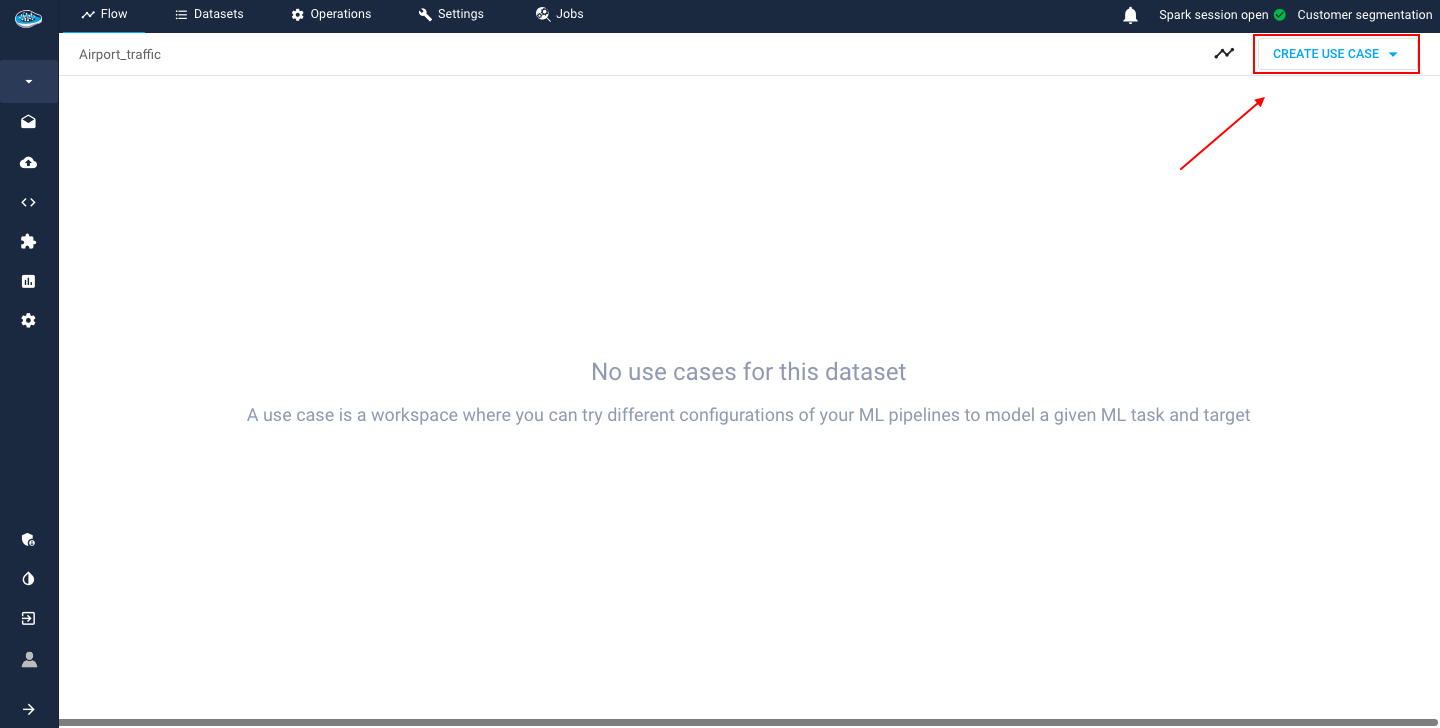
A wizard will be displayed to create interactively your own use case in just 3 easy steps :
-
First step: Select the type of use case you want to resolve from the different options available.
The list of available use case types is the following :Binary Classification, Multi Classification, Regression: to predict a value from a target column that needs to be indicated.Clustering: to detect groups based on some characteristics that the model will automatically find with no target specified.CQR (Conformal Quantile Regression): This specific state-of-the-art type of Regression includes an advanced uncertainty estimation.TS Forecasting: to predict future continuous numerical values like a Regression but related with previously observed values over a period of time.Survival models: a specific type of regression used to estimate the duration time of an event to be occured(such as the death of a patient or an error status of a machine)
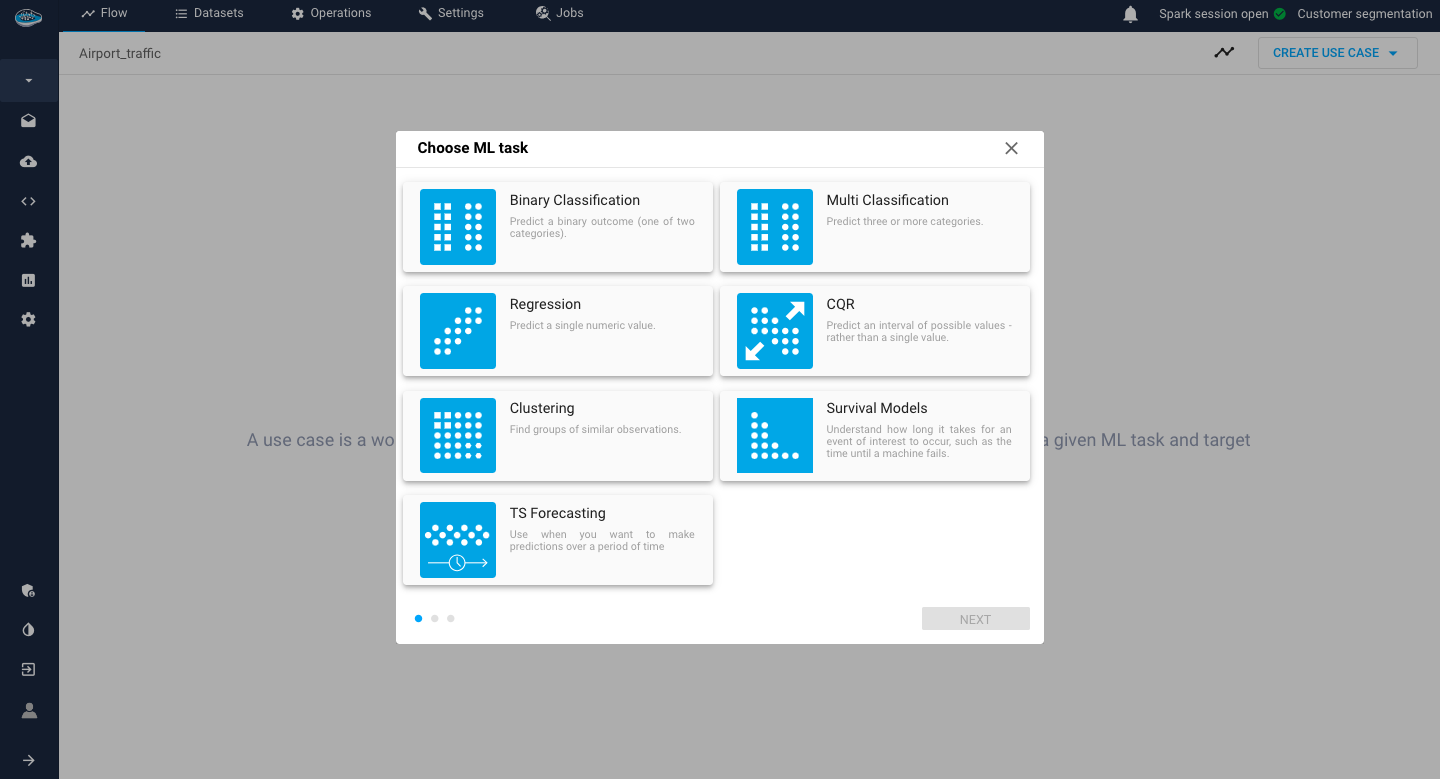
List of available ML tasks for your use case
Warning
For each type of model, a target column is required except for Clustering.
Note
For both Classification types, the platform expect either categorical data or discrete integer values as a target class.
For Regression, the platform expect numerical data as target.Info
Except Clustering and TS Forecasting, some of the available model types require other settings to be indicated by the user :
- For both Classification types and Regression, the transformer applied on the target is required with no transformer option by default
- For CQR, with the target class, you select the desired confidence bounds you want to apply to your prediction
- For Survival models, you need to indicate the survival duration column with the positive outcome and the event status column. -
Second step: When the type of use case is selected, you select (if required) the target class and the transformer to be applied on it. When done, you hit the blue Next button.
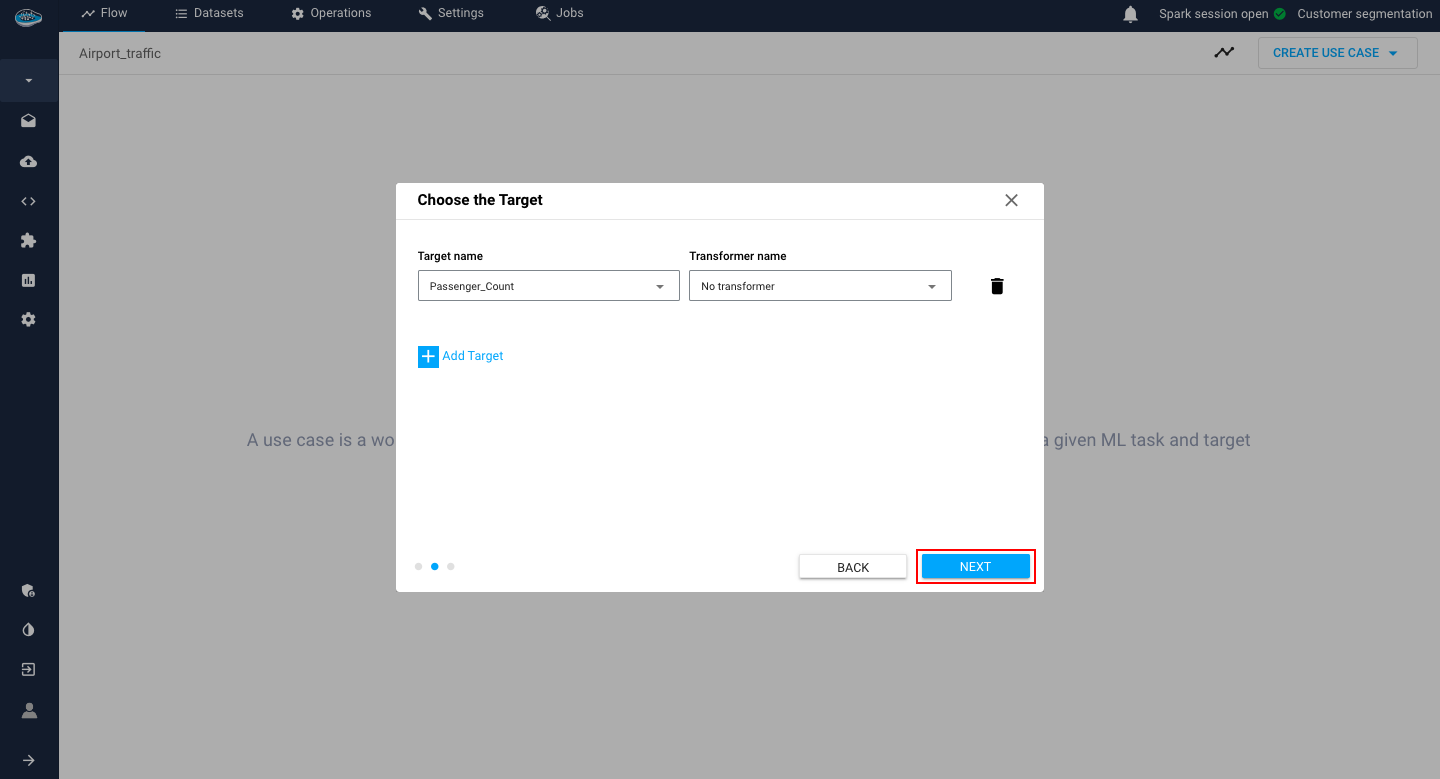
Choose the target and its transformer step Info
The list of available transformers are the following :
- Categorical :LabelEncoder
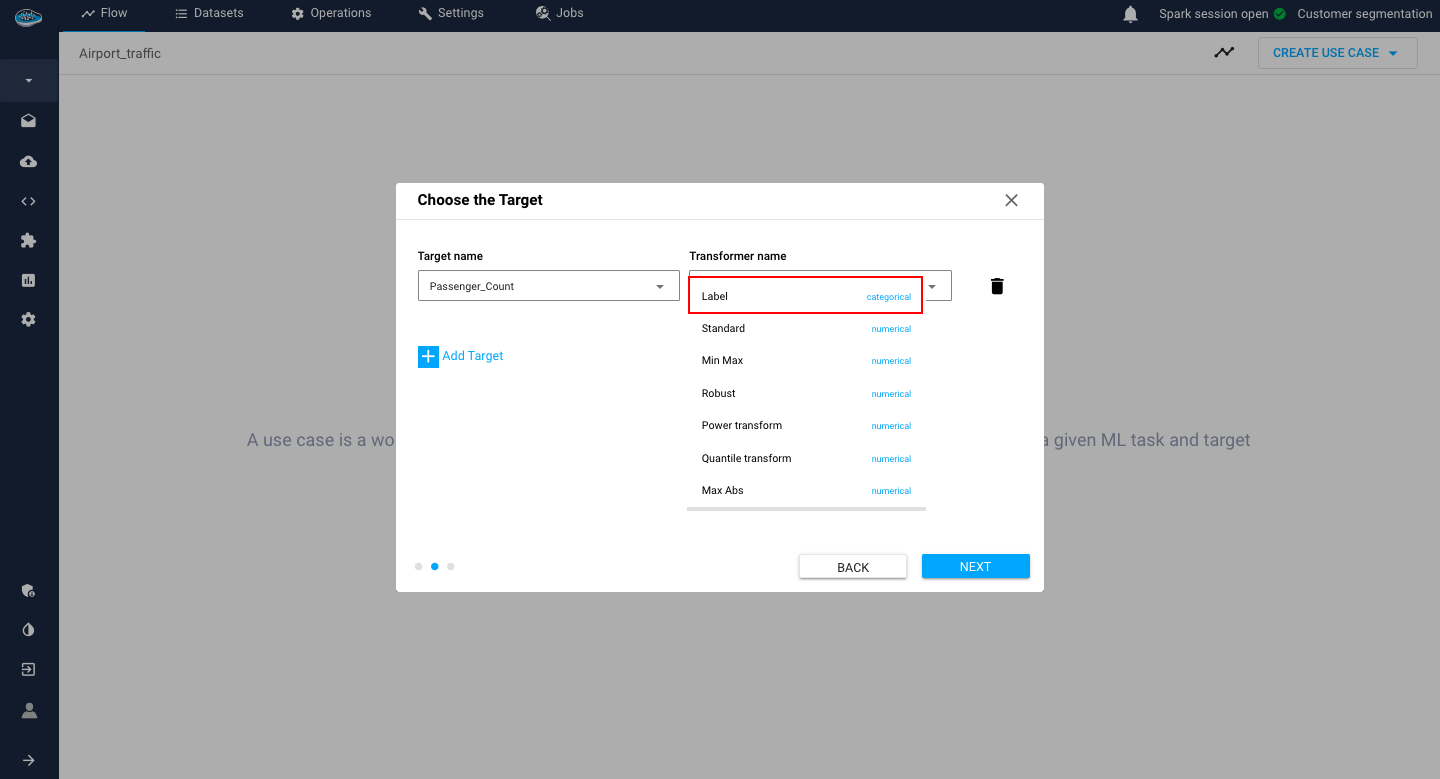
Categorical transformer
- Numerical :Standard, Min Max, Robust, Power transform, Quantile transform, Max Abs
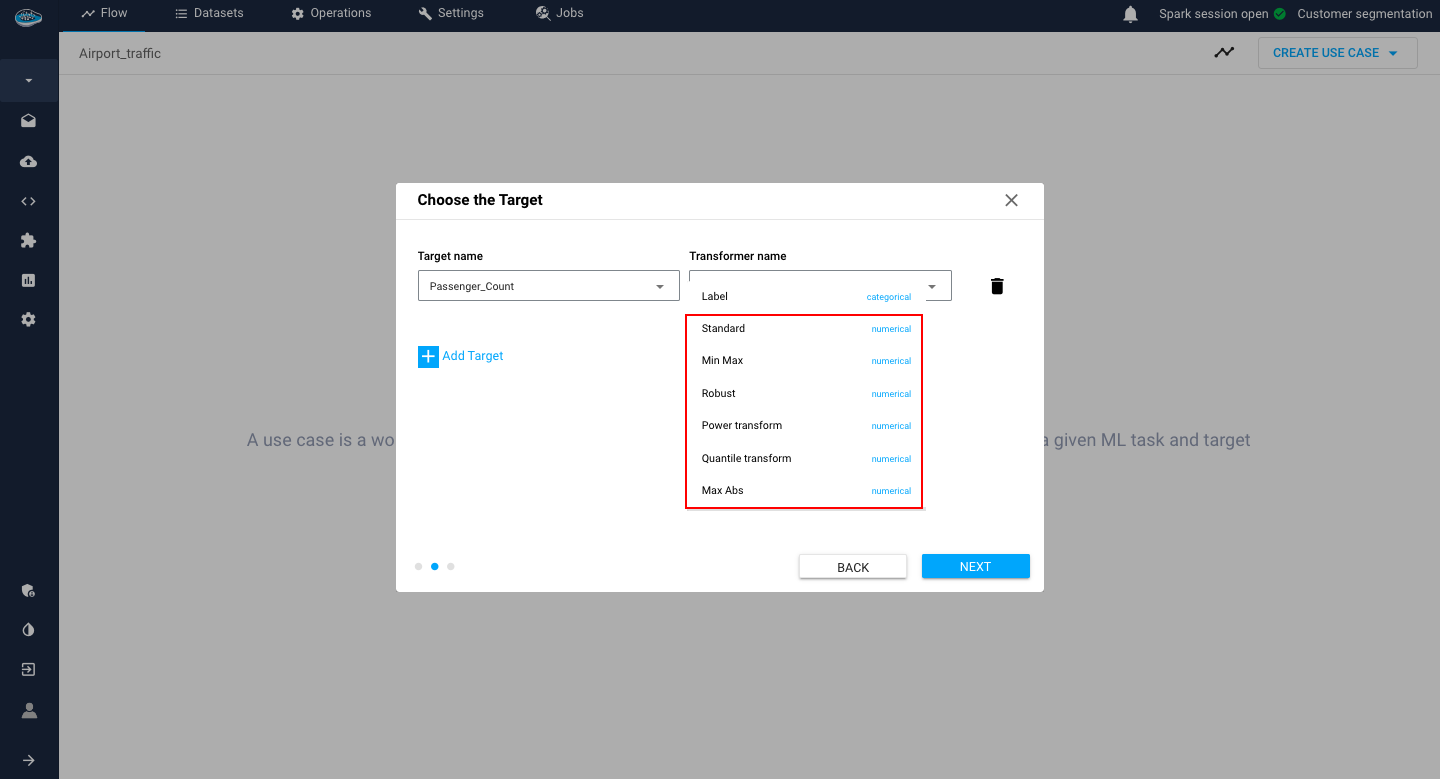
Numerical transformers -
Final step: Type out the name (required), description and tags (optional) of your new use case to finally create it.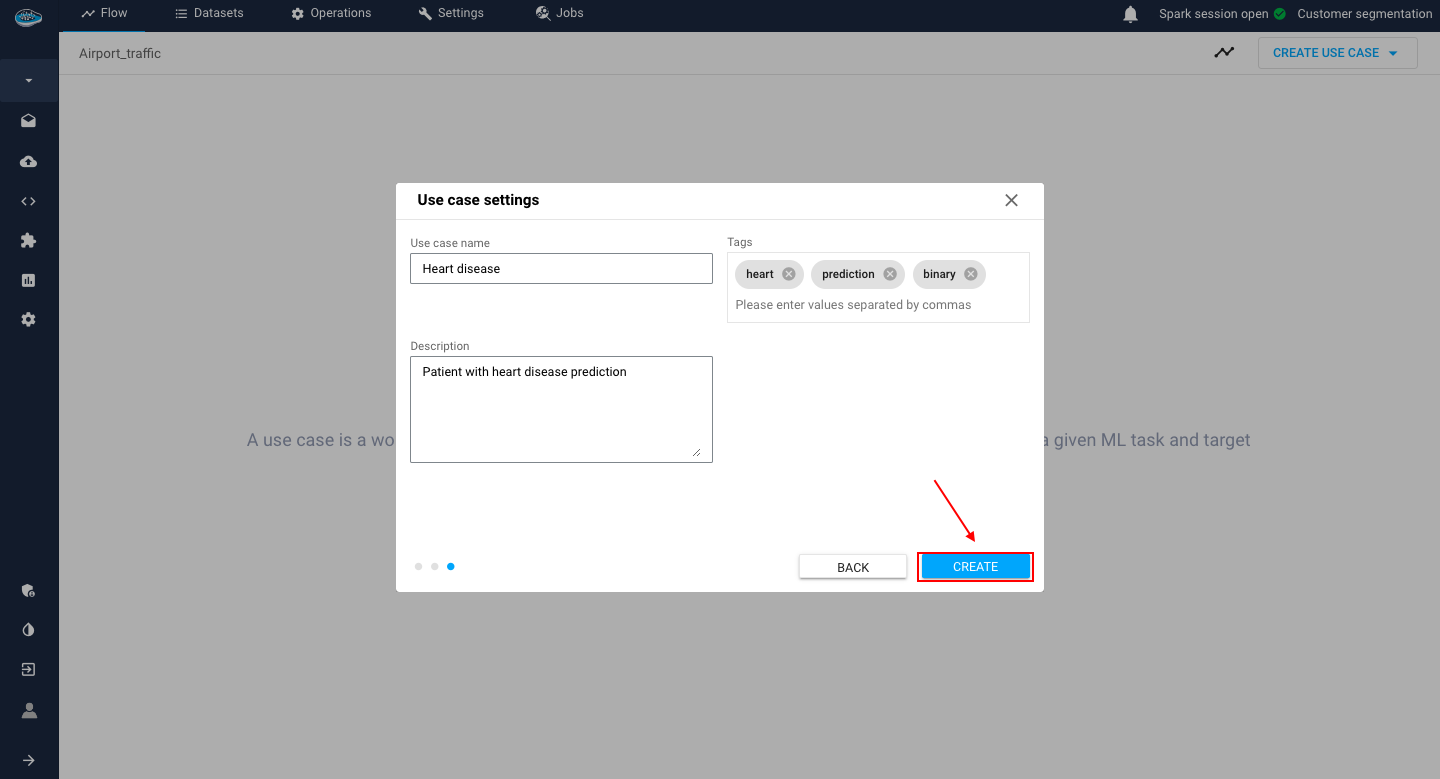
Use case settings step
With the use case created, you get to access to the experiment interface where you test out multiple models and compare them which we are going to talk about next.