Python and/or Spark SQL recipes¶
Data can be imported in many forms just as mentioned before but you can also create your own dataset by coding it.
Thanks to our integrated Python and Spark SQL scripts, you can simply code and create your own dataset to be exported onto your project's flow. Simply click the same Import a new dataset button or the little icon on the top right corner and select your preferred programming language, either Spark SQL or Python (other languages will be added in the future stay tuned...), and the programming interface will appear onto the screen.
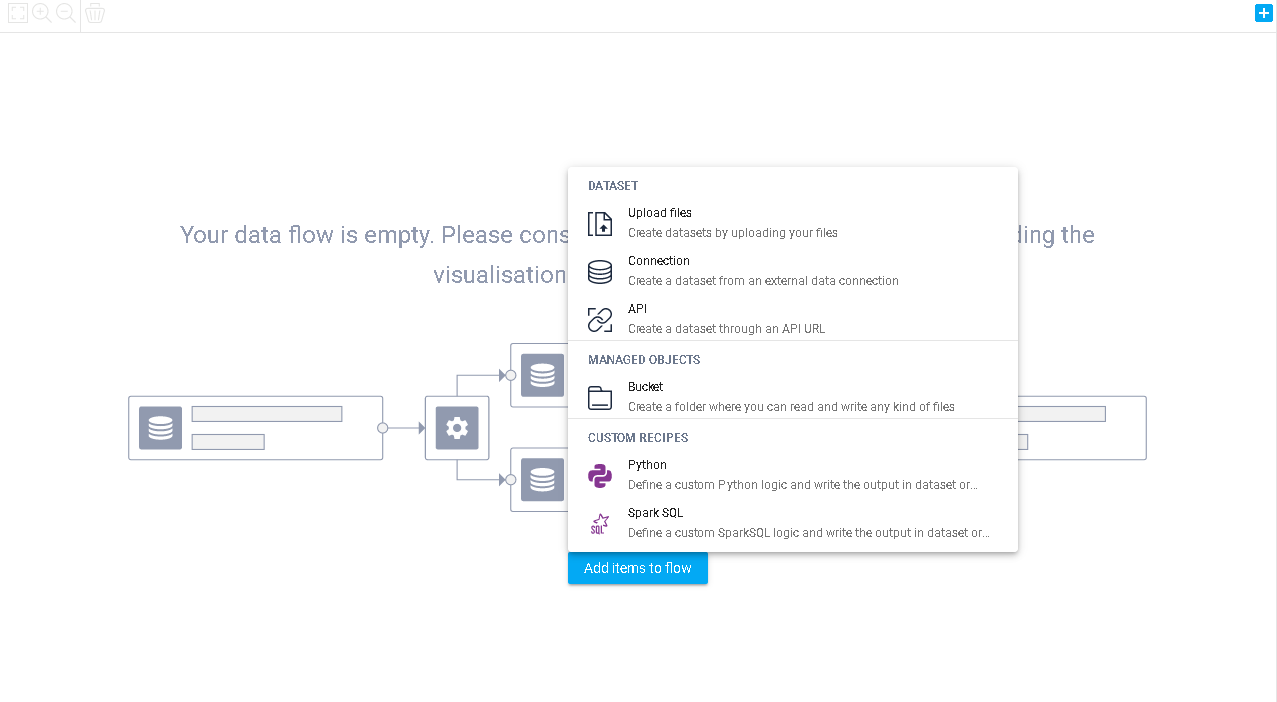
In this interface, you will find a left sidebar with the data inputs and outputs (in this case, you only have outputs). By default, there is only one output but you can add others if needed and you can modify their names. On the right hand side, you have the editor to type in your code. Some lines of codes and some instructions are added by default to help you get started into writing your script correctly.
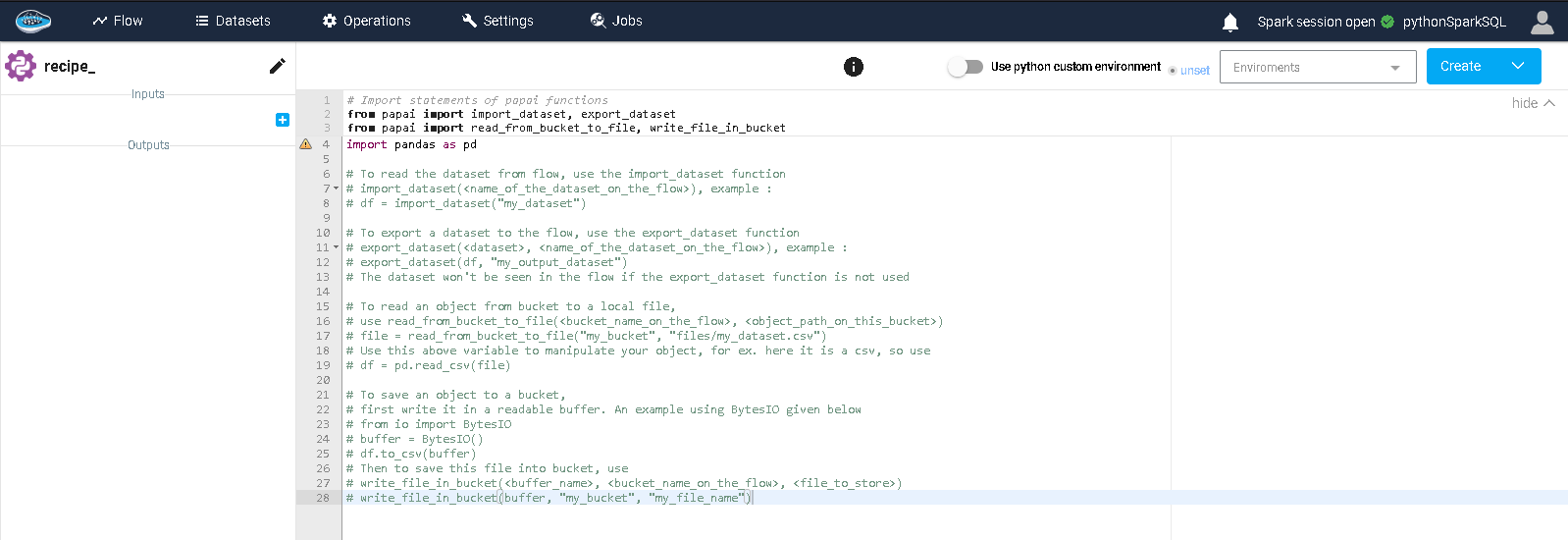
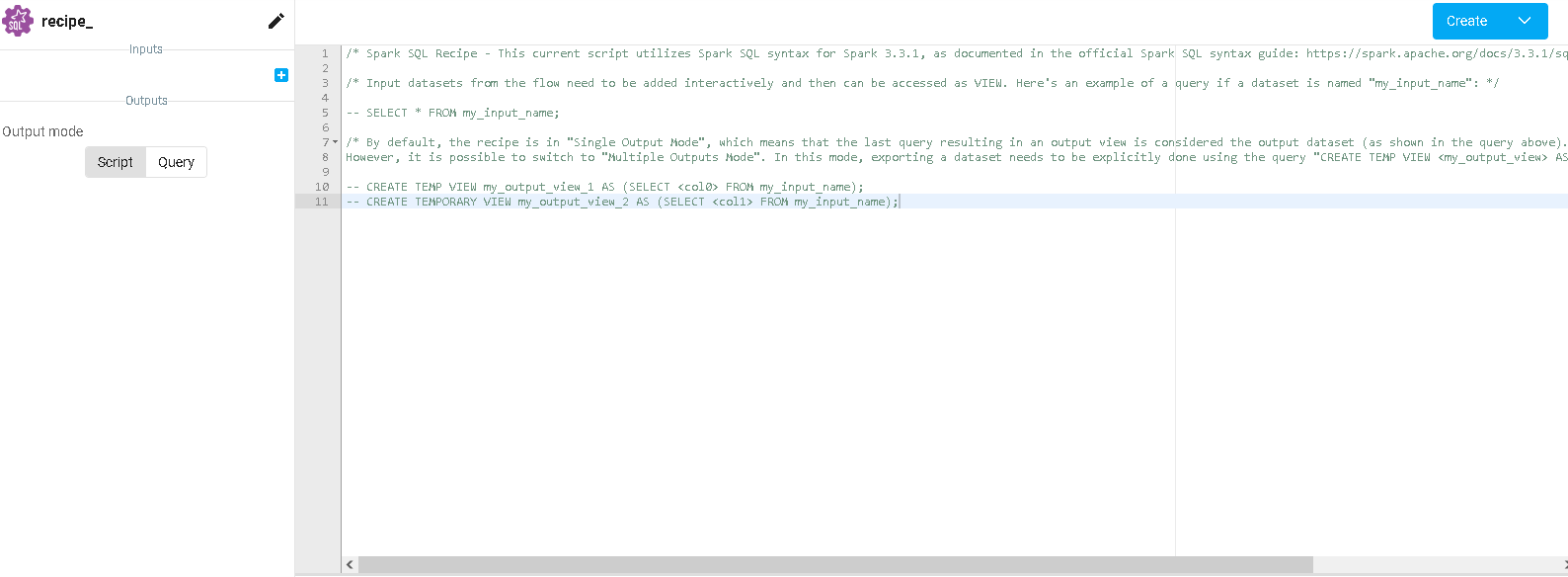
When you finish writing your script, you just click the blue top right button, saying Create and Run, and the script will start running and its status will be displayed in the console located in the bottom part of the page. It will either inform you if the run is successful or it encountered some issues related to your script. When your script is running, the output datasets will appear in your project's flow linked to your newly created Python or Spark SQL script. You can modify the script at your convenience and re-run it with the Save and Run button.
Tip
Don't forget to save your modifications made on your script with the Save and Run button, located on the top right corner screen or else all your progress will be lost and the output dataset won't be refreshed as expected.
Did you know ?
Python script also includes these essential libraries to allow you a great liberty of coding such as : Pandas, NumPy, scikit-learn, lightgbm, category_encoders, xgboost, skorch, torch, lime, shap, requests, psycopg2-binary, sqlalchemy
Note
In case you need other libraries for your script, check this page on virtual environments
Info
If you want to use a script with input datasets, check this page
Developing the python recipe¶
PapAI provides functions to interface with your buckets (see more on buckets).
delete_large_files(bucket_name, remote_path, size_threshold, recursive=False, only_print_files_to_delete=False)
Delete files in a bucket that are larger than a threshold.
Parameters:
-
bucket_name(str) –Name of the bucket to delete files from.
-
remote_path(str) –Path to the files to delete.
-
size_threshold(int) –Number of bytes above which files will be deleted.
-
recursive(bool, default:False) –Whether to delete files recursively in
remote_path, by default
False. -
only_print_files_to_delete(bool, default:False) –If True, disables the deletion of files and only prints the path to
files that would be deleted, by default False.
Examples:
>>> delete_large_files(
... "my-bucket",
... "path/to/",
... 12_000_000,
... only_print_files_to_delete=True,
... )
Would delete "my-bucket/path/to/file1.txt" (15000156 bytes)
Would delete "my-bucket/path/to/file2.txt" (16124156 bytes)
>>> delete_large_files(
... "my-bucket",
... "path/to/",
... 12_000_000,
... recursive=True,
... only_print_files_to_delete=True,
... )
Would delete "my-bucket/path/to/file1.txt" (12000001 bytes)
Would delete "my-bucket/path/to/file2.txt" (1009000145 bytes)
Would delete "my-bucket/path/to/archive/file2.txt" (95408192 bytes)
Would delete "my-bucket/path/to/awesome/marco.txt" (13020153 bytes)
>>> delete_large_files(
... "my-bucket",
... "path/to/",
... 12_000_000,
... )
delete_old_files(bucket_name, remote_path, date_threshold, recursive=False, only_print_files_to_delete=False)
Delete files in a bucket that are older than a given date.
Parameters:
-
bucket_name(str) –Name of the bucket to delete files from.
-
remote_path(str) –Path to the files to delete.
-
date_threshold(datetime) –Date threshold to delete files older than.
-
recursive(bool, default:False) –Whether to delete files recursively in
remote_path, by default
False. -
only_print_files_to_delete(bool, default:False) –If True, disables the deletion of files and only prints the path to
files that would be deleted, by default False.
Examples:
>>> delete_old_files(
... "my-bucket",
... "path/to/",
... datetime.datetime(2021, 1, 1),
... only_print_files_to_delete=True,
... )
Would delete "my-bucket/path/to/file1.txt" (Last modified: 2020-12-31 08:29:02.53157)
Would delete "my-bucket/path/to/file2.txt" (Last modified: 2020-12-31 23:43:32.09876)
>>> delete_old_files(
... "my-bucket",
... "path/to/",
... datetime.datetime(2021, 1, 1),
... recursive=True,
... only_print_files_to_delete=True,
... )
Would delete "my-bucket/path/to/file1.txt" (Last modified: 2020-12-31 08:29:02.53157)
Would delete "my-bucket/path/to/file2.txt" (Last modified: 2020-12-31 23:43:32.09876)
Would delete "my-bucket/path/to/archive/file2.txt" (Last modified: 2019-08-31 23:43:32.09876)
Would delete "my-bucket/path/to/awesome/marco.txt" (Last modified: 2000-07-09 17:51:02.00000)
>>> delete_old_files(
... "my-bucket",
... "path/to/",
... datetime.datetime(2021, 1, 1),
... )
export_dataset(dataset, dataset_name)
Write a pandas DataFrame to a parquet file in the papai bucket.
Parameters:
-
dataset(DataFrame) –Pandas DataFrame to write to the bucket.
-
dataset_name(str) –Name of the dataset to write to.
Examples:
>>> import pandas as pd
>>> df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
>>> export_dataset(df, "my-dataset")
get_from_bucket(bucket_name, remote_paths)
Download files or folders from a bucket to the local file system.
Parameters:
-
bucket_name(str) –Name of the bucket.
-
remote_paths(str | list[str] | GlobPath | list[GlobPath]) –Path or paths to the files or folders in the bucket.
Returns:
-
str | list[str]–Path to the downloaded file or folder in the local file system.
Examples:
>>> file_path = get_from_bucket("my-bucket", "path/to/file.txt")
>>> pathlib.Path(file_path).rglob("*")
"/tmp/83m2a000r0c90o7" # this is the path to the downloaded file
>>> folder_path = get_from_bucket("my-bucket", ["path/file1.txt", "path/to/file2.txt"])
>>> pathlib.Path(folder_path).rglob("*")
["/tmp/2009ma0983rco/file1.txt", "/tmp/2009ma0983rco/file2.txt"]
>>> # content of folder is copied to `folder_path`:
>>> folder_path = get_from_bucket("my-bucket", "path/**")
>>> pathlib.Path(folder_path).rglob("*")
["/tmp/mar9308720009/file1.txt", "/tmp/mar9308720009/to/file2.txt"]
get_input_buckets()
List input buckets step names in the flow.
Returns:
-
list[str]–List of input buckets names.
Examples:
>>> get_input_buckets()
["bucket1", "bucket2"]
get_input_datasets()
List input datasets step names in the flow.
Returns:
-
list[str]–List of input datasets names.
Examples:
>>> get_input_datasets()
["dataset1", "dataset2"]
get_output_buckets()
List output buckets step names in the flow.
Returns:
-
list[str]–List of output buckets names.
Examples:
>>> get_output_buckets()
["bucket_output"]
get_output_datasets()
List output datasets step names in the flow.
Returns:
-
list[str]–List of output datasets names.
Examples:
>>> get_output_datasets()
["dataset_output"]
glob_bucket_objects(bucket_name, pattern)
List files in a remote directory that match a pattern.
Parameters:
-
bucket_name(str) –Name of the bucket to list in.
-
pattern(str) –List all objects that starts with
pattern.
Returns:
-
list[str]–List of object names that match the pattern.
Examples:
>>> glob_bucket_objects("my-bucket", "path/to/file*.txt")
["my-bucket/path/to/file1.txt", "my-bucket/path/to/file2.txt"]
import_dataset(dataset_name)
Load a pandas DataFrame from a parquet file in the papai bucket.
Parameters:
-
dataset_name(str) –Name of the dataset to load.
Returns:
-
DataFrame–DataFrame loaded from the parquet file.
Examples:
>>> df = import_dataset("my-dataset")
>>> repr(df)
DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
list_bucket_objects(bucket_name, prefix='', recursive=True)
List bucket objects with name starting with prefix.
Parameters:
-
bucket_name(str) –Name of the bucket to list in.
-
path(str) –List all objects that starts with
prefix. -
recursive(bool, default:True) –Whether to list files under
prefixrecursively. By default True.
Returns:
-
list[str]–List of object names that match the pattern.
Examples:
>>> list_bucket_objects("my-bucket", "path/to/")
["my-bucket/path/to/file1.txt", "my-bucket/path/to/file2.txt", "my-bucket/path/to/model.json"]
open_bucket_file(bucket_name, file_path, mode, **kwargs)
Open a file in a bucket.
Parameters:
-
bucket_name(str) –Name of the bucket to delete files from.
-
file_path(str) –Path to the file to open.
-
mode(str) –Mode in which to open the file. See builtin
open(). -
kwargs–Additional arguments (such as encoding, errors, newline) to pass to the
filesystem and/or to the TextIOWrapper if file is opened in text mode.
Returns:
-
TextIOWrapper | AbstractBufferedFile–File object.
Examples:
>>> with open_bucket_file("my-bucket", "path/to/file.txt", "r") as f:
... print(f.read())
Hello, world!
>>> import json
>>> with open_bucket_file("my-bucket", "path/to/file.json", "r", encoding="utf-8") as f:
... data = json.load(f)
>>> from PIL import Image
>>> with open_bucket_file("my-bucket", "path/to/image.jpg", "rb") as f:
... img = Image.open(f)
put_to_bucket(bucket_name, local_paths, remote_paths)
Upload files / folders to a bucket.
Parameters:
-
bucket_name(str) –Name of the bucket to upload to.
-
local_paths(PathPattern) –Path to the objects to upload. It can be a glob pattern or a list of
patterns. -
remote_paths(PathPattern) –Path(s) to upload to in the bucket. If it is a list, it must have the
same length aslocal_object_namesand local_paths that are glob
patterns will not be expanded.
Examples:
>>> # puts file at `path/to/file.txt` in the bucket at `file.txt`
>>> put_to_bucket("my-bucket", "path/to/file.txt", "file.txt")
>>> # puts files at `path/to/file1.txt` and `path/to/file2.txt` in the
>>> # bucket at `file1.txt` and `file2.txt`
>>> put_to_bucket(
... "my-bucket",
... ["path/to/file1.txt", "path/to/file2.txt"],
... ["path/to/file1.txt", "path/to/file2.txt"],
... )
>>> # Yields error "No such file or directory" because of `path/to/file*.txt`
>>> put_to_bucket(
... "my-bucket",
... ["path/to/file1.txt", "path/to/file*.txt"],
... ["path/to/file1.txt", "path/to/file2.txt"],
... )
>>> # puts files matching `path/to/file*.txt` in the bucket at `path/to/`
>>> put_to_bucket("my-bucket", "path/to/file*.txt", "path/to/")
put_to_bucket_with_versionning(bucket_name, local_paths, base_versionned_path, remote_path='', version_generator=range(int(100000000000.0)))
Upload files / folders to a bucket. If the remote path already exists,
a suffix will be added to remote_path so that the destination is not
overridden.
Parameters:
-
bucket_name(str) –Name of the bucket to upload to.
-
local_paths(PathPattern) –Path to the objects to upload. It can be a glob pattern or a list of
patterns. -
base_versionned_path(str) –Base path that will be versionned with a suffix.
-
remote_path(PathPattern, default:'') –Path(s) to upload to in the base_versionned_path. If it is a list, it
must have the same length aslocal_paths. By default "". -
version_generator(Iterator[int | str], default:range(int(100000000000.0))) –Generator of version numbers/string to try. You can customize this
to change how the versionned named will be generated. By default
range(10e10).
Returns:
-
str–Path to base_versionned_path with the version added.
Examples:
>>> # If `file_0` and `file_1` already exists in `path/` in the bucket
>>> put_to_bucket_with_versionning("my-bucket", "path/to/file.txt", "file")
file_2
# now the bucket also contains `path/to/file_3.txt`
>>> for _ in range(3):
... path_versionned = put_to_bucket_with_versionning("my-bucket", "path/to/file.txt", "file")
... print(path_versionned)
file_0
file_1
file_2
>>> # If `file_10` and `file_12` already exists in `path/` in the bucket
>>> put_to_bucket_with_versionning("my-bucket", "path/to/file.txt", "file", range(10, 20, 2))
file_14
set_verbose(verbose)
Set the verbosity of the papai_unified_storage module.
Parameters:
-
verbose(bool) –Whether to print debug information.
Examples:
>>> set_verbose(True)
>>> write_to_file_in_bucket("my-bucket", "path/to/file.txt", "Hello, world!")
Writing to file "path/to/file.txt" in bucket "my-bucket"
>>> set_verbose(False)
>>> write_to_file_in_bucket("my-bucket", "path/to/file.txt", "Hello, world!")
write_to_file_in_bucket(bucket_name, file_name, data)
Write data to a file in a bucket.
Parameters:
-
bucket_name(str) –Name of the bucket to write to.
-
object_name(str) –Name of the object to write to.
-
data(bytes | str | BytesIO | StringIO) –Data to write to the object.
Examples:
>>> write_to_file_in_bucket("my-bucket", "path/to/file.txt", "Hello, world!")